딥러닝_03_퍼셉트론, 다층퍼셉트론
[퍼셉트론]
- 퍼셉트론: 선형모델+활성화 함수
- 인간의 뉴런은 모든 자극에 반응하는 게 아니라 자극의 크기가 역치 이상일 때 반응함
*역치: 반응을 일으키기 위한 최소한의 자극의 세기
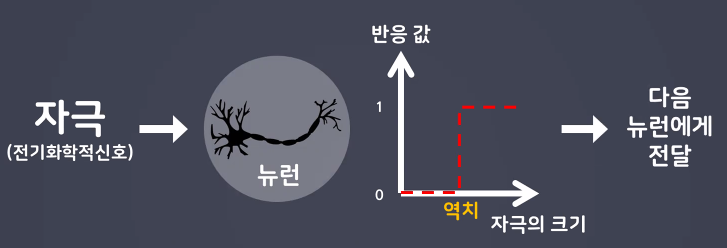
- 역치의 개념을 활성화 함수로 표현

- 입력데이터가 활성화 함수를 통해 자극에 반응할 것인지 결정됨

1)Step function(계단함수): 퍼셉트론에 활용되는 활성화 함수. X값이 0 이하면 y는 0(무반응), 0을 초과하면 1(반응)


2)시그모이드 함수(sigmoid 함수): 경사하강법을 사용할 때 필요한 기울기가 있는 함수
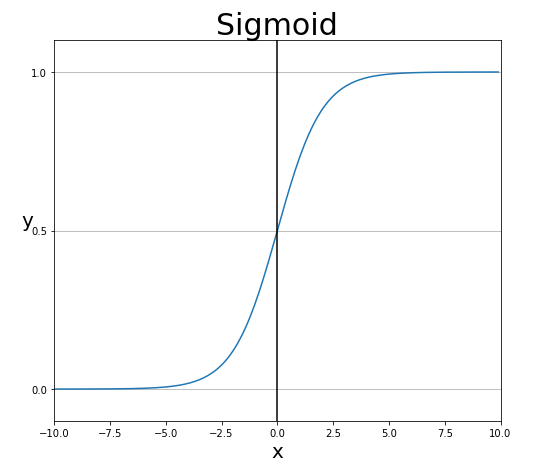
- 경사하강법: 예측값과 정답값 간의 차이인 손실 함수의 크기를 최소화시키는 파라미터를 찾기 위해 최적의 가중치와 절편의 값을 찾는 방법
2. 다층 퍼셉트론(MLP, Multi Layer Perceptron): XOR 문제 해결하기 위해 고안한 퍼셉트론을 여러 개의 층으로 구성하여 만든 신경망
<기존의 퍼셉트론>
- AND 게이트: X1, X2가 모두 참이면 참
- OR 게이트: X1, X2 중 하나가 참이면 참


- XOR 게이트: 하나의 퍼셉트론(선형모델)으로는 해결할 수 없음

- XOR 게이트를 구현한 다층 퍼셉트론의 구조

- NAND: AND 연산의 결과값을 반대로 출력하는 연산

- XOR 게이트를 NAND 연산을 통해 해결할 수 있음

- 다층 퍼셉트론의 구조

- 예측데이터의 종류에 따라 출력층의 개수나 활성화 함수의 종류가 달라짐
-예측데이터가 범주형 데이터→분류
-예측데이터가 연속형 데이터→회귀

- 다층퍼셉트론의 특징
-한 번의 연산으로는 해결되지 않는 문제 해결 예)XOR 게이트
-단층 퍼셉트론에 학습시간이 오래 걸림
-모델(신경망)이 복잡해지면서 과대적합이 발생하기 쉬움
[유방암 분류 실습]
1. 목표
- 환자 데이터를 바탕으로 유방암 여부를 판단하기
- 딥러닝을 통해 이진분류 진행
- sklearn에서 제공하는 load_breast_cance 데이터 사용
#라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2. 데이터 불러오기
#유방암 데이터 가져오기
from sklearn.datasets import load_breast_cancer
#데이터 불러오기
breast_data=load_breast_cancer()
#key 확인
breast_data.keys()
#입력데이터: data
#출력데이터: target
#출력데이터의 종류: target_name
#특성의 이름: feature_names
#데이터 설명
print(breast_data.DESCR)
#30개의 특성(Number of Attributes)과 2개의 클래스(class)를 가진 데이터
#특성의 개수->입력층의 입력특성 개수
#클래스의 개수->분류의 종류 파악(이진/다중분류)
#타겟 이름(결과데이터의 종류) 확인
breast_data.target_names
#malignant: 악성종양[0], benign: 양성종양[1]
3.문제 정답데이터 분리
X=breast_data['data']
y=breast_data['target']
#train/test 데이터 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test=train_test_split(X, y, test_size=0.2, random_state=10)
4.신경망 모델링
1)신경망 모델 구조 설계
2)신경망 학습방법 및 평가방법 설정: 정답데이터의 종류에 따라 달라짐
- 분류: 정답데이터의 종류가 범주형 데이터일 때(이진분류, 다중분류)
- 회귀: 정답데이터의 종류가 연속형 데이터일 때
3)신경망 학습 및 학습결과 시각화
4)모델 예측 및 평가
#tensorflow 모델링 도구 불러오기
from tensorflow.keras.models import Sequential #모델의 뼈대
#신경망의 구성요소
from tensorflow.keras.layers import InputLayer, Dense, Activation
1)신경망 모델 구조 설계: 다층퍼셉트론(신경망모델+활성화함수*n개)
#1. 신경망 모델 구조 설계
#1-1. 뼈대 생성
model=Sequential()
#1-2. 입력층 추가하기(InputLayer)
#입력층에 특성의 개수를 정확하게 입력!
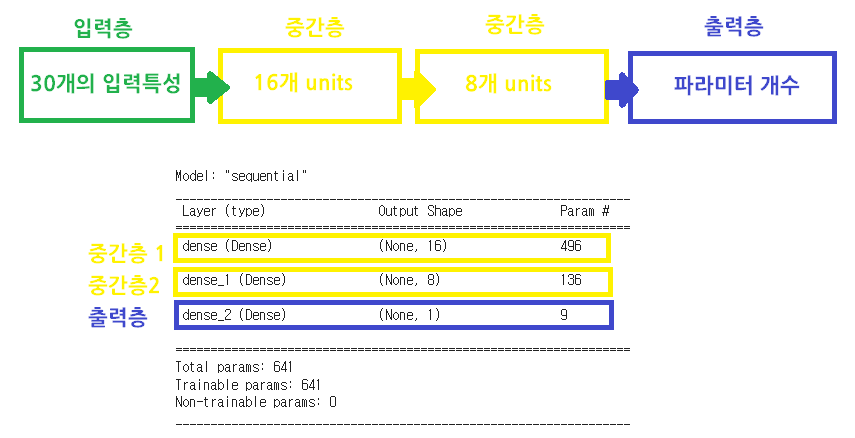
model.add(InputLayer(input_shape=(30,)))
#1-3. 연산층 추가하기(Dense)
#퍼셉트론: 신경망모델(units)+활성화 함수(activation)
#다층퍼셉트론: 퍼셉트론(Dense)을 여러 개 구성
model.add(Dense(units=16, activation='sigmoid'))
model.add(Dense(units=8, activation='sigmoid'))
#1-4. 출력층 추가하기(Dense)
model.add(Dense(units=1, activation='sigmoid'))
#이진분류: 하나의 퍼셉트론과 sigmoid 활성화 함수를 추가함
2)신경망 학습방법 및 평가방법 설정
#2. 모델 학습 및 평가 방법 설정
#이진분류모델
#최적화 손실함수:binary_crossentropy
#최적화 알고리즘: Adam
#평가방법: accuracy(정확도)
model.compile(loss='binary_crossentropy',
optimizer='Adam',
metrics=['accuracy']
)
3)신경망 학습 및 학습결과 시각화
#3. 신경망 학습 및 학습결과 시각화
breast_history=model.fit(X_train, y_train,
validation_split=0.2,
epochs=100)
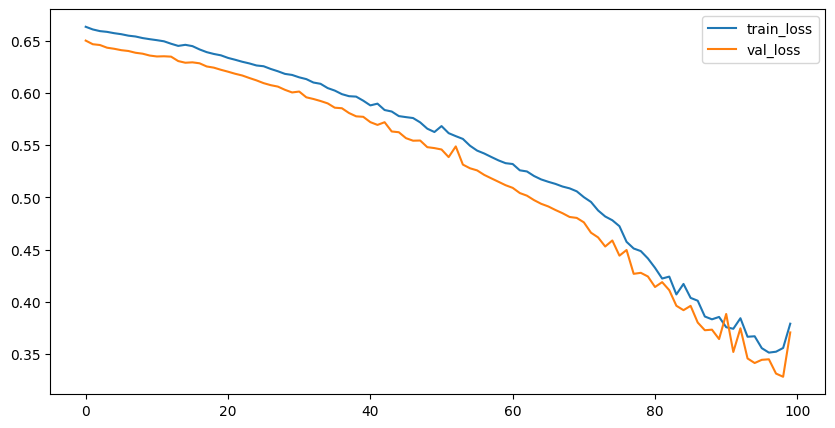
#학습결과 시각화
plt.figure(figsize=(10,5))
plt.plot(breast_history.history['loss'], label='train_loss')
plt.plot(breast_history.history['val_loss'], label='val_loss')
plt.legend()
plt.show()
#모델에 대한 전체적인 내부 구조 확인
model.summary()
#Layer, Parameter 확인
#y=w1x+w2x2....+b
#dense Param=17(30개의 입력특성(가중치)+절편 1개)x8(선형모델의 개수)=496
#dense1 Param=17(16개의 입력특성(가중치)+절편 1개)x8(선형모델의 개수)=136
#출력층(dense2) Output Shape->결과값
#분류의 결과값->확률
#->50%를 기준으로 50% 미만이면 0, 50% 이상이면 1
'코딩 > 딥러닝' 카테고리의 다른 글
| [DL]6. CNN (0) | 2023.09.20 |
|---|---|
| [DL]5. 오차 역전파 (0) | 2023.09.15 |
| [DL]4. 다중분류 (0) | 2023.09.14 |
| [DL]2. 딥러닝 개요 (0) | 2023.09.09 |
| [DL]1. 텍스트 마이닝 (0) | 2023.09.06 |