1. 크롤링: Web상에 존재하는 Contents를 수집하는 일련의 과정
2. 크롤링 라이브러리
1)requests 라이브러리
-접근할 웹페이지의 데이터를 요청 및 응답받기 위한 라이브러리
- 라이브러리 불러오기
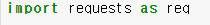
- 요청하기: req.get('요청할 주소')
- 응답의 종류
-Response [200]번대: 성공적으로 요청 및 응답을 받음
-Response [400]번대: 클라이언트(요청) 측에서 오류 발생
-Response [500]번대: 서버(응답) 측에서 오류 발생
- 페이지 html 문서만 추출: res.text(String 타입)
2)beautifulsoup 라이브러리: 복잡한 html문서(tag soup)를 컴퓨터가 이해할 수 있는
객체로 변경해주는 라이브러리
- 라이브러리 불러오기

- request 라이브러리로 추출한 페이지 html 문서 객체화
-bs.(가공할 html 문서, '가공방법')

-lxml: 빠르고 관대한 parsing(가공) 방법
[실습1]네이버 검색페이지에서 ‘메뉴’ 크롤링하기

1. 페이지 요청하기: req.get('요청할 주소')
2. 페이지 html 문서 가져오기: 요청한 변수명.text 예)res2.text
3. html 문서 객체화: bs(html 문서, ‘가공방법’) 예)soup2=bs(res2.text, ‘lxml;)
4. html 문서 중 원하는 요소만 추출하기: 태그 찾기-태그 불러오기
1)원하는 요소의 태그 찾기
-방법1.가져오고 싶은 contents 선택-우측 마우스-검사


-방법2. 개발자 도구에서 커서모양 아이콘 클릭하고 원하는 contents 클릭하기
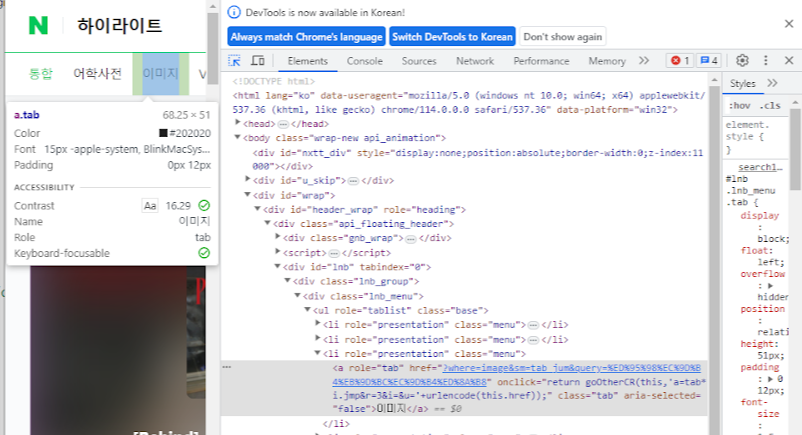
2)태그 불러오기: select(‘태그명’)
- select: 여러 요소를 복수형(list타입)으로 가져옴
-사용방법: 객체화 변수명.select('태그명')
-태그명만 입력할 경우 해당 태그 전부를 불러옴 예) soup2.select('a')
-특정 태그만 가져오고 싶으면 class 선택자 활용 예)soup2.select('a.tab')
- select_one: 여러 요소 중 맨 위에 있는 요소만 단수형으로 가져옴
-사용방법: 객체화 변수명.select_one('태그명')
3)특정 태그만 불러오기: class 선택자 활용하여 태그 불러온 후 인덱싱
-사용방법: 객체화 변수명.select('태그명.class명')[인덱스 번호]
예)naver_img=soup2.select('a.tab')[2]
4)태그 중 contents만 불러오기: 태그 인덱싱.text 예)naver_img.text
[실습2]날씨 검색 후 현재 온도 데이터 수집
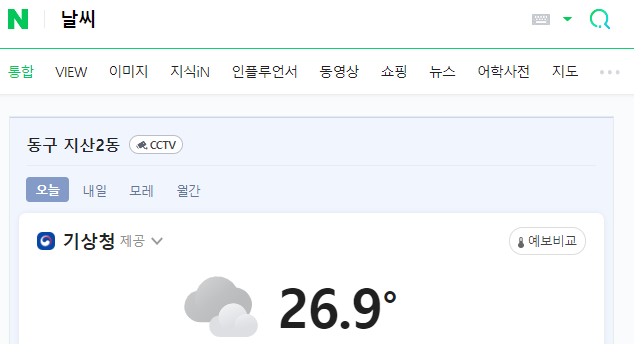
1. 페이지 정보 불러오기
url='https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=
0&ie=utf8&query=%EB%82%A0%EC%94%A8'
naver=req.get(url)
2. html 문서 객체화
naver.text
tag=bs(naver.text, 'lxml')
3. 원하는 태그 선택하기
weather=tag.select('div.temperature_text')[0]
4. contents 출력
weather.text 또는
weather[0].text 인덱싱을 출력 시 해도 됨
'코딩 > 크롤링' 카테고리의 다른 글
| [크롤링]5. 이미지 데이터 수집 (0) | 2023.07.04 |
|---|---|
| [크롤링]4. selenium 실습 (0) | 2023.06.29 |
| [크롤링]3. selenium 라이브러리 (0) | 2023.06.28 |
| [크롤링]2. 크롤링 실습 (0) | 2023.06.27 |