머신러닝_06_Decision Tree
캐글에서 데이터 다운로드
https://www.kaggle.com/datasets/uciml/mushroom-classification
- Decision Tree: 특정 기준(질문)에 따라 데이터를 구분하는 모델
-스무고개 하듯이 예/아니오 질문을 반복하면 학습
-분류와 회귀에 모두 사용 가능
- 장점: 쉽고 직관적인 모델
- 단점: 과대적합이 발생하기 쉬움→사전 가지치기 필요(트리의 크기 사전 제한)

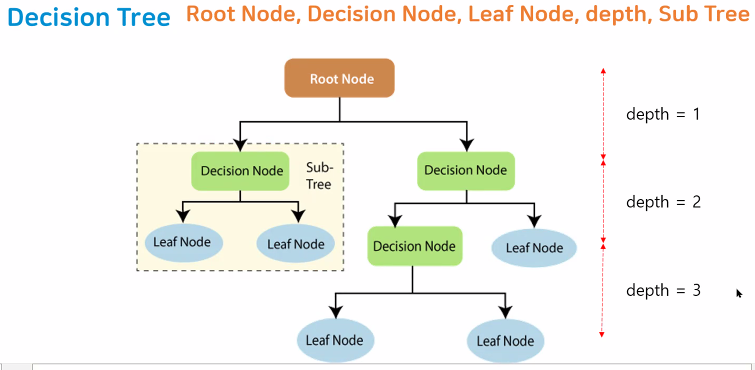
- Decision Tree 구조
-Root Node: 가장 상위에 있는 규칙노드. 첫 번째 규칙 조건
-Decision Node: 규칙 노드
-Leaf Node: 규칙노드에 의해 결정된 클래스 값
-depth: 트리의 깊이
-Sub Tree: 규칙 노드에 의해 분류된 클래스값을 포함한 그룹

- Decision Tree 불순도 측정: Gini(지니불순도)

- 매개변수: 튜닝 시 사용할 옵션

- 과대적합 제어: 모델 생성 시 매개변수 옵션을 사용해 과대적합 방지


2. 데이터 변환하기: 범주형→숫자형 데이터 변환
1)One-hot-Encoding: 분류하고자 하는 범주만큼 자릿수를 만들어 1과 0으로 채워 수치화하는 방식
-단점: 컬럼의 개수가 늘어나 필요없는 메모리 증가

2)Label Encoding: 레이블을 숫자로 mapping하여 변환
-단점: 문자에 대응하는 숫자를 일일이 입력해야 하며, 숫자에 따라 가중치를 매기기 때문에 원하는 결과가 다를 수 있음

3. 모델 일반화 성능평가
1)Cross validation: 검증데이터를 하나로 고정하지 않고 TEST 데이터의 모든 부분 사용
-데이터의 양이 적더라도 과대적합을 방지할 수 있음
-모든 train 데이터를 test에 활용할 수 있음→모델 정확도 향상
(기존의 방식)

(Cross validation)

[단계]
- train 데이터를 k개의 그룹으로 나누기
- K-1개의 그룹을 학습에 사용
- 나머지 1개의 그룹을 평가에 활용
- 2~3번 과정을 k번 반복
- 모든 결과의 평균 구하기
- 장점
-모든 test 데이터셋을 훈련에 활용할 수 있음
→정확도 향상, 데이터 부족으로 인한 과소적합 방지
-모든 test 데이터셋을 평가에 활용할 수 있음→평가에 사용되는 데이터 편중 방지, 평가 데이터셋 과대적합 방지
- 단점
-여러 번 학습하고 평가하는 과정이 필요하여 모델훈련/평가 시간이 오래 걸림
2)GirdSearchCV
- 사용자가 모델과 hyper parameter 지정
- GirdSearchCV 함수가 순차적으로 hyper parameter들을 변경하면서 학습, 평가 수행
- 가장 성능이 좋은 hyper parameter 제시
[실습]버섯 분류
https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database

1. 문제 정의
- 버섯의 특징을 활용하여 독버섯/식용 버섯 분류
- Decision Tree 시각화/과대적합 속성 제어(하이퍼 파라미터 튜닝)
- 특징 선택
2. 데이터 불러오기
#파일 불러오기(구글 드라이브 마운트 방식)
import pandas as pd
data=pd.read_csv('/content/drive/MyDrive/실습파일/머신러닝실습/Data/mushrooms.csv')
#데이터 구조 살펴보기
data.head()
#데이터 크기 확인
data.shape
#데이터 정보 확인
data.info()
#데이터 타입 object->숫자 형태로 변환 필요!(Label Encoding, One-hot-Encoding)
#컬럼의 중요도 확인->히트맵, 그래프 등
3. 데이터 전처리
1)문제와 답 분리하기
#loc로 분리하기
X=data.loc[ :, 'cap-shape': ]
y=data.loc[ : ,'class']
- 데이터 기술통계량 확인
# 기술통계량 확인
X.describe()
#count: 데이터 개수
#unique: 중복되지 않은 데이터의 개수
#top: 최빈값
#freq: 최빈값 개수
- 데이터 유형별 건수 확인
#유형별 건수 확인
X['cap-shape'].value_counts()
- 중복되지 않은 값 확인
#중복되지 않은 값 확인
X['cap-shape'].unique()

2)인코딩
- one-hot-encoding: 범주형→수치형 데이터로 변환
#pd.get_dummies(): one-hot-Encoding 함수
X_one_hot=pd.get_dummies(X)
X_one_hot
#컬럼의 수 22->117개 증가
- 라벨 인코딩(lable_Encoding)
-딕셔너리 문자들을 숫자로 변환
-부여된 숫자에 따라 가중치를 줄 수 있기 때문에 자주 사용하지 않음
X['habitat'].unique()
#라벨 인코딩 방법
#문자와 대응하는 숫자 데이터를 담은 딕셔너리 생성
habitat_dic={'u': 1,'g': 2,'m': 3,'d': 4,'p':5,'w': 6, 'l':7}
#실제 데이터 반영->map() 함수
X['habitat'].map(habitat_dic)
3)데이터 분할
- 훈련 세트 평가 세트 분할
- trian_test_split(): 랜덤으로 섞고 일정 비율로 나누는 역할(7:3)
- random_state: 랜덤하게 섞는 규칙, 고정값
#데이터 분할
#train_test_split 불러오기
from sklearn.model_selection import train_test_split
#X_train, X_test, y_train, y_test=train_test_split("X", y, test_size=0.3, random_state=6)
#X->X_one_hot으로 변경(원래 데이터 대신 수치화된 문제 데이터 삽입)
X_train, X_test, y_train, y_test=train_test_split(X_one_hot, y, test_size=0.3, random_state=6)
4. 모델 선택 및 생성
#DecisionTree 모델 import
from sklearn.tree import DecisionTreeClassifier
#DecisionTree 모델 생성
tree_model=DecisionTreeClassifier()
5. 모델 성능평가
1)cross_val_score
# cross_val_score import
from sklearn.model_selection import cross_val_score
#cross_val_score(모델, X, y, cv=나눌 개수)
result=cross_val_score(tree_model, X_train, y_train, cv=5)
result

2)GridSearchCV(모델 생성/학습/평가)
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
import pandas as pd
cvtree_model=DecisionTreeClassifier()
#파라미터
#max_depth 3,5,7
#max_leaf_nodes 4,6,8
#min_samples_split 1000,2000,3000
#min_samples_leaf 400, 500, 600
params={
'max_depth': [3,5,7],
'max_leaf_nodes': [4,6,8]
}
#GridSearchCV(모델이름, param_grid=파라미터, cv=cv값, refit=T/F )
#refit: 가장 좋은 파라미터 설정을 재학습
grid_tree=GridSearchCV(cvtree_model, param_grid=params,cv=5, refit=True)
#param_grid에서 설정한 파라미터를 순차적으로 학습/평가
grid_tree.fit(X_train, y_train)
#grid_tree
#best_params_
print('최적의 하이퍼 파라미터', grid_tree.best_params_)
print('최고 교차 검증 점수: ', grid_tree.best_score_)
print('최고 성능 모델: ', grid_tree.best_estimator_)

#grind 결과 추출
grid_result=pd.DataFrame(grid_tree.cv_results_)
#일부 컬럼만 출력하기
grid_result[['params', 'mean_test_score', 'rank_test_score', 'split0_test_score']]
#정확도 평가
#accurage_score(실제값, 예측값)
#예측하기
#정답 데이터 predict(X)
from sklearn.metrics import accuracy_score
#최적 모델 가져오기->best_estimator_
best_model=grid_tree.best_estimator_
#예측
pre=best_model.predict(X_test)
pre
#평가
score=accuracy_score(y_test, pre)
print('최적의 모델 정확도: {0:4f}'.format(score))

6. 모델 학습
#모델 학습(fit)
tree_model.fit(X_train, y_train)
7. 모델 평가
- 모델 성능 평가
#모델 성능 평가
#.score(input_data, true_data)
tree_model.score(X_test, y_test)
- 모델 예측
#모델 예측(predict)
pre=tree_model.predict(X_test)
pre
- 모델 정확도
#모델 정확도
#accuracy_score(실제값, 예측값)
from sklearn.metrics import accuracy_score
accuracy_score(y_test,pre)
8. 시각화: graphviz 라이브러리 설치(jupyter Notebook 사용하는 경우)
#graphviz 라이브러리 import
import graphviz
#모델 모양 출력파일 만들기
from sklearn.tree import export_graphviz
export_graphviz(tree_model, #학습된 모델
out_file='tree.dot', #출력파일 이름(확장자 .dot)
class_names=['독버섯', '식용 버섯'], #분류명(정답데이터 이름)
feature_names=X_one_hot.columns, #컬럼명(특징 이름)
impurity=True, #지니불순도 출력
filled=True #내부 색상 출력
)
#모델 출력
with open('/content/tree.dot', encoding='UTF-8') as f:
dot_graph=f.read()
display(graphviz.Source(dot_graph))
9. 과대적합 제어(하이퍼 파라미터 튜닝)
- max-depth: 트리의 깊이 제한
- max_leaf_nodes: 리프 노드의 최대 개수
- min_samples_split: 노드를 분할하기 위한 최소 샘플 수 제한
- min_samples_leaf: 리프 노드(결과값)가 가져야할 최소 샘플 수
#모델 선택(깊이 제한, 최소 샘플 수 제한)
tree_model3=DecisionTreeClassifier(max_depth=5, min_samples_split=100)
#모델 학습(fit)
tree_model3.fit(X_train, y_train)
#모델2 성능 평가(깊이 제한 후)
#.score(input_data, true_data)
tree_model2.score(X_test, y_test)

#모델 모양 출력파일 만들기
from sklearn.tree import export_graphviz
export_graphviz(tree_model3, #학습된 모델
out_file='tree3.dot', #출력파일 이름(확장자 .dot)
class_names=['독버섯', '식용 버섯'], #분류명(정답데이터 이름)
feature_names=X_one_hot.columns, #컬럼명(특징 이름)
impurity=True, #지니불순도 출력
filled=True #내부 색상 출력
)
#모델 출력
with open('/content/tree3.dot', encoding='UTF-8') as f:
dot_graph=f.read()
display(graphviz.Source(dot_graph))
10. 특성 선택: tree 모델의 특성 중요도 확인
# 특징 선택 feature_importances_
fi=tree_model.feature_importances_
#DataFrame으로 만들기
importance_df=pd.DataFrame(fi, index=X_one_hot.columns)
#컬럼의 중요도 파악
importance_df.sort_values(by=0, ascending=False)
11. 중요도 시각화
#데이터 시각화 라이브러리 불러오기
import matplotlib.pyplot as plt
import seaborn as sb
import pandas as pd
#특징 선택 .feature_importances_
importance_value=tree_model.feature_importances_
#Series로 만들기
im_series=pd.Series(importance_value, index=X_one_hot.columns)
im_series_top=im_series.sort_values(ascending=False)[:20]
#시각화
plt.figure(figsize=(15,10))
plt.title('Feature importance top 20')
#막대그래프
sb.barplot(x=im_series_top, y=im_series_top.index)
plt.show()

[개인 실습]
당뇨병 진단
https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database
'코딩 > 머신러닝' 카테고리의 다른 글
| [ML]8. 타이타닉호 생존자 예측 모델 (0) | 2023.08.25 |
|---|---|
| [ML]7. 앙상블 모델 (0) | 2023.08.18 |
| [ML]5. KNN 모델(Iris 데이터) (0) | 2023.08.16 |
| [ML]4. 데이터 핸들링(Titanic 실습) (0) | 2023.08.14 |
| [ML]3. 머신러닝 과정 실습 (0) | 2023.08.10 |