머신러닝_08_타이타닉 생존예측모델
- 문제정의
- 타이타닉호 생존자, 사망자 예측
- 머신러닝 전체 모델과정 진행
- train.csv 파일로 훈련, test.csv 파일로 예측
- 제출용 샘플데이터 gender_submission.csv 형식에 맞게 제출
#라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
2. 데이터 수집
Kaggle 사이트에서 Titanic - Machine Learning from Disaster 데이터 수집
#train 데이터 불러오기
train_data=pd.read_csv('/content/drive/MyDrive/실습파일/머신러닝 실습/Data/train.csv')
#테스트 데이터 불러오기
test_data=pd.read_csv('/content/drive/MyDrive/실습파일/머신러닝 실습/Data/test.csv')
#데이터 확인
train_data.info()
print()
test_data.info()
#Survived->정답 데이터
3. 데이터 전처리
# Train_data 컬럼
# Survived : 생존여부 (생존 1, 사망 0)
# Pclass : 승객 객실 등급
# Name : 이름
# Sex : 성별
# Age : 나이
# SibSp : 동승자 중 형제, 배우자 수
# Parch : 동승자 중 부모, 자녀 수
# Ticket : 티켓 번호
# Fare : 탑승 요금
# Cabin : 객실 번호
# Embarked 승선지 (C 프랑스_셰르부르, Q 아일랜드_퀸스타운(현.코브), S 영국_사우스햄튼)
3-1. 결측치 확인(.isna)
-train: Age/Cabin/Embarked
-test: Age/Cabin/Fare
#boolean 인덱싱으로 Age가 NaN인 데이터 확인->isna()
#전체데이터[확인할 컬럼.isna()]
train_data[train_data['Age'].isna()]
#기술통계량 확인->값의 범위 확인
train_data['Age'].describe()
3-2. 결측치 처리
3-2-1. Age(train, test_data) 결측치 채우기
-특징: 나이의 범위가 너무 넓어 평균값을 넣기 어려움, 데이터의 분포도가 한 곳으로 치우침→다른 컬럼과 엮어서 상관관계 확인 후 채우기
- 상관관계 확인
#상관관계: 각 특성간 영향도를 수치로 표현한 것(-1~1)
#양의 상관관계(1), 음의 상관관계(-1), 상관관계 없음(0)
#corr()->수치형 데이터의 상관관계
train_data.corr()
- 히트맵으로 상관관계 시각화하기
#히트맵으로 상관관계 확인
import matplotlib.pyplot as plt
import seaborn as sns
#상관관계 행렬계산
hmap=train_data.corr()
#히트맵 그리기
plt.figure(figsize=(8,6)) #크기 설정
#heatmap(데이터, annot, cmap)
#cmpap 옵션: virdis, plasma, cividis, coolwarm, YlGnBu
sns.heatmap(hmap, annot=True, cmap='YlGnBu')
plt.show()

- 피벗 테이블로 시각화하기
#피벗 테이블: 데이터를 요약하고 분석하기 위해 사용되는 도구
#Pclass, Sex 별 Age 평균데이터
#.pivot_table(values='데이터 기준', index='데이터 기준', aggfunc='데이터 계산방법')
pt1=train_data.pivot_table(values='Age',index=['Pclass', 'Sex'],
aggfunc='mean') #aggfunc option='mean, sum, count'
#멀티인덱싱: 피벗테이블 특정 데이터 추출->loc
pt1.loc[2, 'male']
- Age 결측치 채우기
-조건: Pclass, Sex별 Age 평균
-함수를 이용하여 피벗테이블 값을 결측치에 채우기
#함수 만들기
def fill_age(data): #data(임의의 데이터): 한 행의 데이터
if pd.isna(data['Age']): #Age 결측치가 있다면
return pt1.loc[data['Pclass'], data['Sex']]
#Pclass, Sex별 평균나이 값을 리턴
else: #Age 결측치가 없다면
return data['Age']
#결측치 채우기(train, test)
#함수 적용하기 .apply
#타입 변경하기 .astype()
train_data['Age']=train_data.apply(fill_age, axis=1).astype("int64")
test_data['Age']=test_data.apply(fill_age, axis=1).astype("int64")
3-2-2. Embarked(train_data) 결측치 채우기
- 데이터 범위 확인
#유형별 건수 확인->값의 범위 확인
train_data['Embarked'].value_counts()
- 가장 많이 나온 데이터로 결측치 채우기
#문자열 데이터 채우기-> .fillna()
train_data['Embarked']=train_data['Embarked'].fillna('S')
3-2-3. Fare(test_data) 결측치 채우기
- 데이터 범위 확인
#기술통계량 확인->값의 범위 확인
test_data['Fare'].describe()
#요금 격차가 큼($0~512), 대다수 요금이 최소값($31)에 몰려있음
#->결측치를 전체 평균으로 채우기에는 신뢰성이 떨어짐
- 데이터 상관관계 확인
#수치형 데이터 상관관계 확인->.corr()
test_data.corr()
#상관관계 높은 컬럼->Plcass와 Fare
- 히트맵으로 상관관계 시각화
#그래프(히트맵)로 상관관계 확인
import matplotlib.pyplot as plt
import seaborn as sns
#상관관계 행렬계산
hmap2=test_data.corr()
#히트맵 그리기
plt.figure(figsize=(8,6)) #크기 설정
#heatmap(데이터, annot, cmap)
#cmpap 옵션: virdis, plasma, cividis, coolwarm, YlGnBu
sns.heatmap(hmap2, annot=True, cmap='YlGnBu')
plt.show()

- 피벗 테이블로 시각화하기
#피벗 테이블: 데이터를 요약하고 분석하기 위해 사용되는 도구
#Pclass, Sex 별 Age 평균데이터
#.pivot_table(values='데이터 기준', index='데이터 기준', aggfunc='데이터 계산')
pt2=test_data.pivot_table(values='Fare',
index=['Pclass', 'Sex'],
aggfunc='mean') #aggfunc='mean, sum, count'
pt2
- 결측치 확인(.isnull)
#결측치 확인->.isnull()
test_data[test_data['Fare'].isnull()]
- Fare 결측치 채우기(.fillna): 평균값으로 채우기
#결측치 채우기->fillna()
#티켓 가격 평균으로 채우기
test_data['Fare']=test_data['Fare'].fillna(11.826350)
3-2-4. Cabin(train, test) 결측치 채우기
- 데이터 확인
#중복되지 않은 값 확인
train_data['Cabin'].unique()
- 새로운 Deck 컬럼 만들기: Cabin 컬럼의 결측치에 ‘M’을 채운 컬럼
#새로운 컬럼 생성
train_data['Deck']=train_data['Cabin'].fillna('M')
test_data['Deck']=test_data['Cabin'].fillna('M')
- 문자+숫자로 조합된 데이터 문자로만 변경하기
#문자+숫자 중 첫번째 문자만 가져오기->str[index]
#C85->C
train_data['Deck']=train_data['Deck'].str[0]
test_data['Deck']=test_data['Deck'].str[0]
- 기존의 Cabin 컬럼 삭제하기
#Cabin 컬럼 삭제->.drop()
# **axis 필수**
train_data.drop('Cabin', axis=1, inplace=True)
test_data.drop('Cabin', axis=1, inplace=True)
4. EDA(탐색적 데이터 분석)
1)범주형 데이터 : countplot()
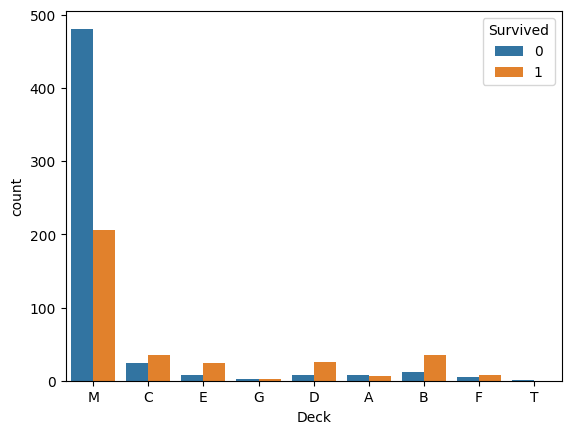
(1)Deck별 생존여부 시각화
- 그룹별 집계
#Deck, Survived 열을 기준으로 Name 컬럼 그룹화하고
#그룹별 데이터 집계,요약->groupby().count()
train_data_group=train_data[['Deck', 'Survived', 'Name']].groupby(['Deck', 'Survived']).count()
train_data_group
- 피벗테이블
#피벗 테이블로 만들기
train_data.pivot_table(values='Name', index=['Deck', 'Survived'],
aggfunc='sum')
- 빈도그래프(Counplot) 시각화
#빈도그래프 시각화
import matplotlib.pyplot as plt
import seaborn as sns
#countplot: 데이터 개수 출력
sns.countplot(data=train_data,x='Deck',hue='Survived')
#M(결측치)에서 상대적으로 사망률이 높음
(2)Pclass별 생존 여부 시각화
- 등급별 생존 여부 시각화
sns.countplot(data=train_data, x='Pclass',hue='Survived' )
ass)가 높아질수록 사망률이 높아짐

- 등급별로 사용한 선실 시각화
# Pclass 기준으로 어떤 선실(Deck) 쓰는지 확인
sns.countplot(data=train_data, x='Deck', hue='Pclass')

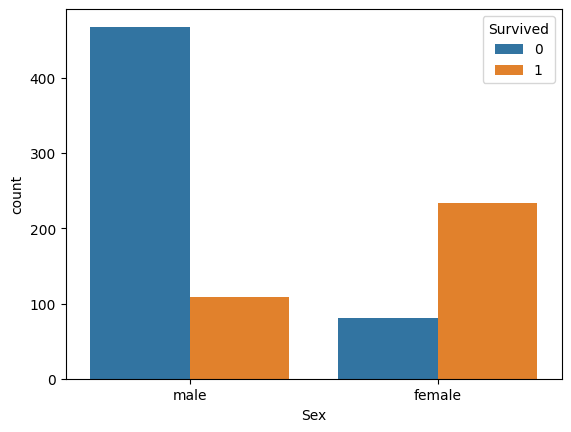
(3)Sex별 생존여부 시각화
#성별 생존 여부 시각화
sns.countplot(data=train_data, x='Sex', hue='Survived')
#남성보다 여성의 생존율 높음
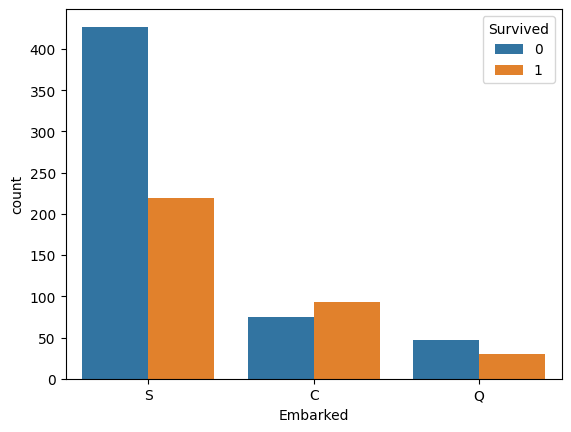
(4) Embarked별 생존여부 시각화
#승선지별 생존 여부 시각화
sns.countplot(data=train_data, x='Embarked', hue='Survived')
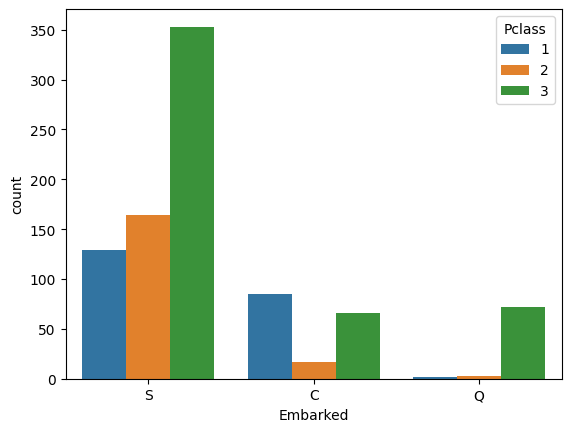
#등급별 승선지 시각화
sns.countplot(data=train_data, x='Embarked', hue='Pclass')
2)수치형 데이터: Violinplot()
(1)Age 컬럼 시각화
#Age 컬럼 시각화
plt.figure(figsize=(15,5))
sns.violinplot(data=train_data, x='Sex', y='Age', hue='Survived', split=True)
plt.grid()
#20-30대에 편중하여 사망함

(2)Fare 컬럼 시각화
#Fare 컬럼 시각화
plt.figure(figsize=(15,5))
sns.violinplot(data=train_data, x='Sex', y='Fare', hue='Survived', split=True)
plt.grid()

(3)SibSp, Parch 컬럼→가족 컬럼으로 병합
-SibSp: 동승한 형제자매
-Parch: 동승한 부모자식
- 가족 컬럼 생성하기: SibSp 컬럼+Parch 컬럼+자기 자신
#부모데이터+형제자매 데이터+자기 자신을 더하여 가족 컬럼 만들기
train_data['Family_size']=train_data['SibSp']+train_data['Parch']+1
test_data['Family_size']=test_data['SibSp']+test_data['Parch']+1
- 가족 컬럼 시각화
#등급별 가족컬럼 데이터 개수 출력->countplot
sns.countplot(data=train_data,x='Family_size', hue='Pclass')

#가족별 생존여부 데이터 개수 출력->countplot
sns.countplot(data=train_data,x='Family_size', hue='Survived')

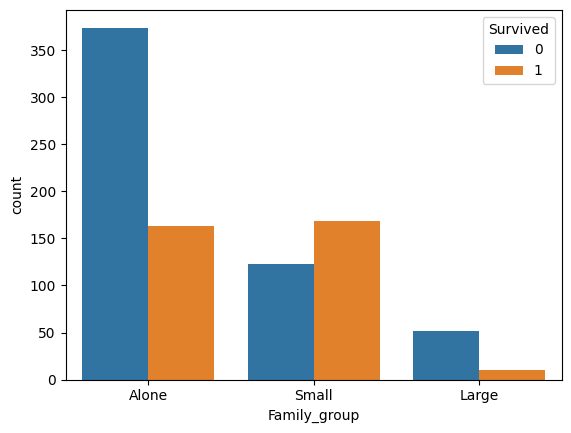
- 가족 컬럼 범주형 데이터로 변환
-1명-→Alone
-2~4명→Small
-5명 이상→ Large
#데이터를 나눌 경계선 설정, 시작점 미포함, 끝점 포함
bin_size=[0, 1, 4, 11]
#구간별 이름 설정
label=['Alone', 'Small', 'Large']
#데이터 범주화하기->cut
#cut 옵션->bins: 범주의 경계, labels: 범주의 이름
train_data['Family_group']=pd.cut(train_data['Family_size'], bins=bin_size, labels=label)
test_data['Family_group']=pd.cut(test_data['Family_size'], bins=bin_size, labels=label)
#새로운 컬럼->category 타입
#범주화한 후 그래프시각화
sns.countplot(data=train_data, x='Family_group',hue='Survived' )
5. 데이터 정규화
1) Name 컬럼 데이터 정리하기: 풀네임을 호칭만 남기기
- 이름에서 호칭만 분리하기: 마침표와 쉼표를 기준으로 호칭 분리하기
#split('')
#마침표를 기준으로 이름을 나누고 다시 쉼표를 기준으로 나누기
train_data['Name'][0].split('.')[0].split(',')[1].strip()

- 이름 분리하는 함수 만들기
#이름 분리 함수
def split_name(data): #data: 한 행 기준
return data.split('.')[0].split(',')[1].strip()
- 이름 분리한 데이터로 새로운 컬럼 만들기
#컬럼 생성
#train_data['Age']=train_data.apply(fill_age, axis=1).astype("int64")
#시리즈 형태이므로 axis 옵션이 필요 없음
train_data['Title']=train_data['Name'].apply(split_name)
test_data['Title']=test_data['Name'].apply(split_name)
- 다양한 호칭 간단하게 정리하기
-가장 많이 언급된 호칭 확인
#호칭 시각화
#가장 많이 언급된 호칭 확인
plt.figure(figsize=(15,5))
sns.countplot(data=train_data, x='Title',hue='Survived' )

-가장 많이 언급된 호칭만 남기고 나머지 호칭은 ‘other’로 변경하기
#호칭 배열
title=['Mr', 'Mrs', 'Miss', 'Master', 'Don', 'Rev', 'Dr', 'Mme', 'Ms','Major', 'Lady', 'Sir', 'Mlle', 'Col', 'Capt', 'the Countess','Jonkheer']
#기존 호칭 중 가장 많이 언급된 호칭(5개)+나머지 호칭(12개)으로 분리
#나머지 호칭->other로 변경
#[사용할 호칭]+[바꿀호칭]*바꿀 개수
convert_title=['Mr', 'Mrs', 'Miss', 'Master']+['other']*12
#기존 호칭과 변경할 호칭 묶기->.zip
#zip: 같은 위치에 있는 요소들을 순서대로 묶어서 새로운 딕셔너리 생성
#zip('원본', '변경값')
title_dict=dict(zip(title, convert_title))

#Title 컬럼에 기존-새 호칭 딕셔너리를 매핑(train)
train_data['Title']=train_data['Title'].map(title_dict)
#test 데이터 'Dona' 딕셔너리에 추가하여 'other'로 변경
title_dict['Dona']='other'
#Title 컬럼에 새로 만든 호칭 딕셔너리를 매핑(test)
test_data['Title']=test_data['Title'].map(title_dict)
2)Ticket 컬럼 삭제하기
#Ticket 컬럼 데이터 확인
train_data['Ticket'].unique()
#값들의 패턴을 찾을 수 없음
#티켓 컬럼 삭제
train_data.drop('Ticket', axis=1, inplace=True)
test_data.drop('Ticket', axis=1, inplace=True)
3)필요없는 컬럼 삭제하기
#형제자매, 부모, 이름, 가족 개수 컬럼 삭제
train_data.drop('Name', axis=1, inplace=True)
test_data.drop('Name', axis=1, inplace=True)
train_data.drop('SibSp', axis=1, inplace=True)
test_data.drop('SibSp', axis=1, inplace=True)
train_data.drop('Parch', axis=1, inplace=True)
test_data.drop('Parch', axis=1, inplace=True)
train_data.drop('Family_size', axis=1, inplace=True)
test_data.drop('Family_size', axis=1, inplace=True)
6. 문제/정답 데이터 분할
#문제 데이터(Train)
X_train=train_data.drop('Survived', axis=1)
#정답 데이터(train)
y_train=train_data['Survived']
1)One-hot-Encoding: Sex, Embarked, Deck, Family_group, Title 컬럼
#범주형 데이터 one-hot-Encoding
#변환할 컬럼: Sex, Embarked, Deck, Family_group, Title
cat_feature=['Sex', 'Embarked', 'Deck', 'Family_group', 'Title']
# X_train 범주형 데이터 원핫 인코딩(train)
# pd.concat 원-핫 인코딩된 dummy 데이터프레임을 기존의 X_train 데이터프레임에 열 방향으로 결합합니다
for cat_name in cat_feature:
dummy = pd.get_dummies(train_data[cat_name], prefix=cat_name)
X_train = pd.concat([X_train, dummy], axis = 1)
# 원-핫 인코딩에 사용한 카테고리 변수 cat_name 를 삭제해 주세요
X_train.drop(cat_name, axis =1, inplace = True)
# X_test 범주형 데이터 원 핫 인코딩(test)
# pd.concat 원-핫 인코딩된 dummy 데이터프레임을 기존의 X_train 데이터프레임에 열 방향으로 결합합니다
for cat_name in cat_feature:
dummy = pd.get_dummies(test_data[cat_name], prefix=cat_name)
X_test = pd.concat([X_test, dummy], axis = 1)
# 원-핫 인코딩에 사용한 카테고리 변수 cat_name 를 삭제해 주세요
X_test.drop(cat_name, axis =1, inplace = True)
2)문제/정답 데이터 컬럼 일치시키기
#문제/정답 데이터 컬럼 일치시키기
X_train.drop('Deck_T', axis=1, inplace=True)
#컬럼 수 맞는지 확인
set(X_train)-set(X_test)
#컬럼 순서 맞추기
X_test=X_test[X_train.columns]
'코딩 > 머신러닝' 카테고리의 다른 글
| [ML]10. 선형회귀모델 (0) | 2023.08.30 |
|---|---|
| [ML]9. 분류평가지표 (0) | 2023.08.29 |
| [ML]7. 앙상블 모델 (0) | 2023.08.18 |
| [ML]6. Decision Tree 모델 (0) | 2023.08.17 |
| [ML]5. KNN 모델(Iris 데이터) (0) | 2023.08.16 |