머신러닝_10_선형회귀모델
- 선형회귀모델(Linear Model)
- 회귀분석은 예측값이 평균과 같이 일정한 값으로 돌아가려는 경향을 이용한 통계학 기법 이용
- 입력특성에 대한 선형함수를 만들어 예측 수행
- 분류와 회귀에 모두 사용가능

예)7시간 공부할 경우 성적은 몇 점일까?


→y=10x+0일 때 이상적
1)선형회귀함수


2)MSE(평균제곱오차)

- cost function(비용함수)

*cost값이 0이 되게 하는 게 좋은 모델

- 경사하강법: 평균제곱오차가 최소인 w(가중치)와 b(편향)을 찾는 방법
-learning rate: 기울기를 감소하는 속도 조절


[선형회귀모델 실습]
1. 문제정의: 선형회귀모델의 w(가중치),b(절편) 확인하기
#라이브러리 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 선형회귀모델 불러오기
from sklearn.linear_model import LinearRegression
2.데이터 만들기
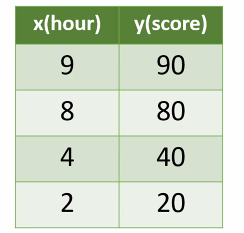
#데이터 프레임 생성
data=pd.DataFrame([[2,20], [4,40], [8,80], [9,90]],index=['A', 'B', 'C', 'D'],columns=['시간', '점수'] )
3.모델링: 선형회귀모델 학습, 예측 시 문제데이터(X)는 반드시 2차원 데이터형태
#모델링
lr_model=LinearRegression()
#모델 학습
#특징이 1개인 경우 시리즈별로 문제 데이터와 정답 데이터를 분리할 수 있음
#시간->문제, 점수->정답
lr_model.fit(data[['시간']],data['점수'])
4.경사하강법(가중치, 절편 찾기)
#가중치-> .coef_
print('모델가중치: ', lr_model.coef_)
#절편-> .intercept_
print('모델의 절편: ', lr_model.intercept_)
5.모델예측
#예측
#시간이 7일 때 점수 예측
lr_model.predict([[7]])
2. 회귀모델 평가지표 종류
1)평균제곱오차(MSE): 0에 가까울수록 좋은 회귀모델

2)평균제곱근 오차(RMSE)

3)평균절대비율오차(MAPE)
- 예측값과 실제값을 뺀 오차를 실제값으로 나눈 값의 평균
- 백분율로 표현하여 RMSE의 단점을 해결

4)R2 Score: 1에 가까울수록 좋은 회귀모델

- 회귀 직선이 평균에 비해 얼마나 그 데이터를 잘 설명할 수 있는지에 대한 점수
- 편차: 예측값과 평균과의 거리
- 오차: 예측값과 회귀직선과의 거리
- 일반적으로 0과 1사이의 값, 예측이 심하게 벗어나면 -값 나올 수 있음
◎예측오차의 크기가 중요하면→RMSE/MAE 사용
◎상대적인 오차의 중요성의 높으면→MAPE
◎모델의 설명력을 강조하려면→R2 Score
[보스턴 주택가격 예측회귀실습]
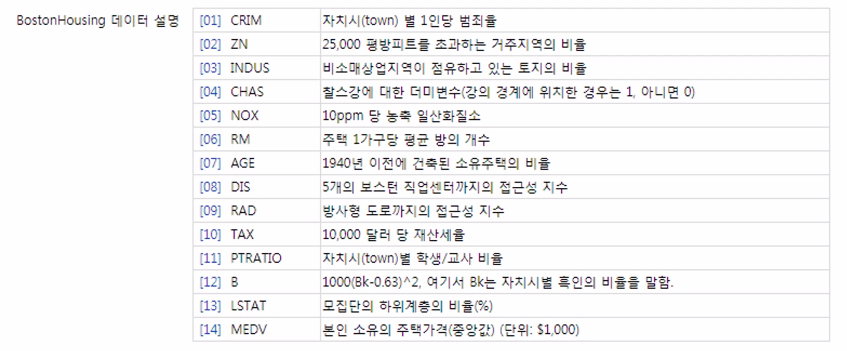
1. 문제정의: 특성변수 활용하여 주택가격 회귀 예측
2. 데이터 불러오기
boston=pd.read_csv('/content/drive/MyDrive/실습파일/머신러닝실습/Data/boston_housing.csv')
boston.info()
3.데이터 전처리
- 필요없는 컬럼 삭제
boston.drop('Unnamed: 0', axis=1, inplace=True)
- 문제/정답 데이터 분할
X=boston.drop('MEDV', axis=1)
y=boston['MEDV']
4. 상관관계 분석
#컬럼별 상관관계 분석
X.corr()
#히트맵으로 상관관계 확인하기
plt.figure(figsize=(15,15))
sns.heatmap(data=X.corr(),
annot=True, #상관계수 히트맵에 표시
annot_kws={'size' :12}, #상관계수 글자 크기
fmt='.2f', #소수점 제한
cmap='Blues'
)
- 학습용/테스트용 데이터 분할
from sklearn.model_selection import train_test_split
#데이터 분할
X_train, X_test, y_train, y_test=train_test_split(X, y, test_size=0.3, random_state=10)
5.모델링
# 선형회귀모델 불러오기
from sklearn.linear_model import LinearRegression
#모델 생성
lr_model=LinearRegression()
#모델 학습
lr_model.fit(X_test, y_test)
#교차검증
from sklearn.model_selection import cross_val_score
#cross_val_score(모델이름, 문제데이터, 정답데이터, cv(분할))
result=cross_val_score(lr_model, X_train, y_train, cv=5)
print('교차검증', result) #데이터 편중
print('교차검증 평균', result.mean())
6. 가중치, 편향 확인
#가중치, 편향(절편) 확인
print('가중치: \n', lr_model.coef_)
print('편향: ', lr_model.intercept_)
7. 회귀모델 평가지표(MES, MAE,RMSE, R2score)
#평가지표 불러오기
from sklearn.metrics import mean_absolute_error #평균절대오차
from sklearn.metrics import mean_squared_error #평균 제곱오차
from sklearn.metrics import r2_score #결정계수, R2스코어
#RMSE(평균제곱근오차): MSE(평균제곱오차)에 루트 씌우는 함수 사용->np.sqrt()
#평균절대오차
mean_absolute_error(y_test, pre)
#MSE(평균 제곱오차)
mean_squared_error(y_test,pre)
#RMSE(평균제곱근 오차)
np.sqrt(mean_squared_error(y_test,pre))
#R2 Score
r2_score(y_test, pre)
#score 함수: 분류->f1-score, 회귀->f2-score 사용
'코딩 > 머신러닝' 카테고리의 다른 글
| [ML]12. 로지스틱 회귀모델 (0) | 2023.09.01 |
|---|---|
| [ML]11. 모델 정규화 (0) | 2023.08.31 |
| [ML]9. 분류평가지표 (0) | 2023.08.29 |
| [ML]8. 타이타닉호 생존자 예측 모델 (0) | 2023.08.25 |
| [ML]7. 앙상블 모델 (0) | 2023.08.18 |