머신러닝_11_모델 정규화
- 특성곱
- 선형회귀모델은 특성의 수가 적으면 모델이 단순해져 성능이 저하됨
- 선형회귀모델은 하이퍼 파라미터 조절을 할 수 없음
→각 특성의 데이터를 곱해서 특징의 수를 늘려서 모델의 성능 개선
- 1차 함수 그래프(직선)를 2차 함수 그래프(곡선)그래프로 변환
2. 선형회귀모델 정규화: 선형회귀모델에서 과대적합을 제어하기 위해 w값의 비중 낮춤
- 선형회귀모델이 지나치게 최적화되면 모형계수의 크기도 지나치게 증가함(과적합)
- 선형회귀계수(w) 값에 제약을 주어 모델이 과도하게 최적화되는 현상 방지
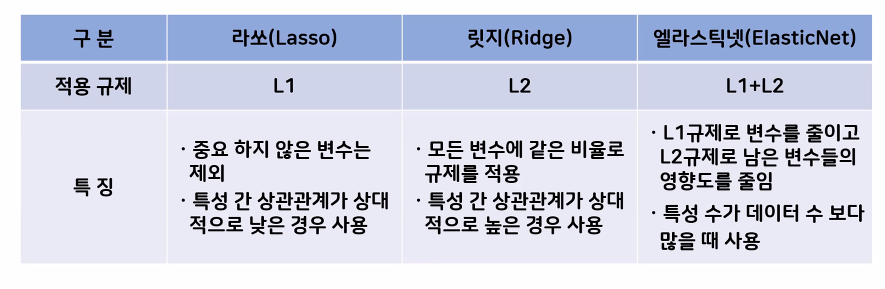
1)Lasso(L1 정규화): 가중치의 절대값의 합을 최소화하는 제약조건
- w의 모든 원소에 똑같은 힘으로 규제를 적용하는 방법
- 불필요한 특성 계수들은 0이 됨(불필요한 특성 삭제)
- 특성 선택이 자동으로 이루어짐
- 특정 특성들의 연관성이 강할 때 사용, 연관성 없는 특성 삭제
2)Ridge(L2 정규화): 가중치의 제곱합을 최소화하는 제약 조건
- w의 모든 원소의 골고루 규제를 적용하여 0에 가깝게 만듦
- 모든 특성들이 연관성이 어느 정도 있을 때 사용, 모든 특성을 골고루 규제
3)엘라스틱넷: L1+L2
- 하이퍼파라미터(강도(alpha), L1, L2 선택하는 비율)
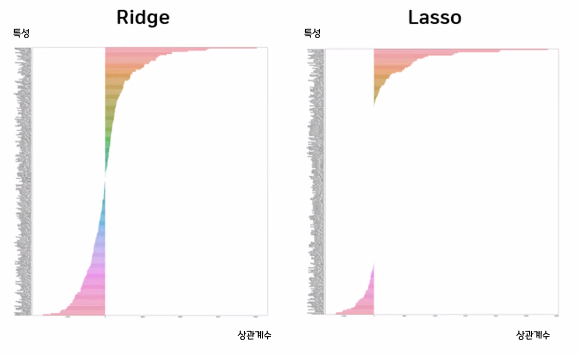
→Ridge는 모든 특성을 규제하지만, Lasso는 연관성 높은 특성만 남겨서 규제함
4)매개변수: alpha(규제의 강도)

[보스턴 주택 가격 예측 실습]
7. 특성곱
- 원본 데이터 가져와서 복사하기
#원본데이터 가져와서 복사하기
#->pandas.DataFrame.copy()
#코드 실행 중 데이터 프레임의 상태 복사하는 기능
boston_copy=boston.copy()
- 컬럼 상관관계 확인하기
#상관계수 확인
boston_copy.corr()
#히트맵으로 상관관계 확인하기
plt.figure(figsize=(15,15))
sns.heatmap(data=boston_copy.corr(),
annot=True, #상관계수 히트맵에 표시
annot_kws={'size' :12}, #상관계수 글자 크기
fmt='.2f', #소수점 제한
cmap='Greens'
)
#MEDV와 상관관계 높은 컬럼->RM(주택의 방 개수), LSTAT(인구 중 하위 계층의 비율)
#특성곱
#1. MEDV와 상관관계 높은 컬럼을 제곱
#2. MEDV와 상관관계 있는 전체 컬럼 제곱
1)LSTAT 컬럼 특성곱 적용
- LSTAT 컬럼만 학습하고 예측한 뒤 시각화하기
#특성곱 확장 전 LSTAT 특성만 가지고 학습하고 예측
#모델링
lr_model=LinearRegression()
#모델 학습
lr_model.fit(X_train[['LSTAT']], y_train)
#모델 예측
pre=lr_model.predict(X_train[['LSTAT']])
#산점도 그래프 그리기
#.scatter(문제 데이터, 답지 데이터)
plt.scatter(X_train[['LSTAT']], y_train) #실제 답
plt.scatter(X_train[['LSTAT']], pre, color='red') # 예측한 답
plt.xlabel('LSTAT')
plt.ylabel('MEDV')
plt.show()
- train 데이터 LSTAT 컬럼에 특성곱 적용 후 학습하고 예측한 뒤 시각화하기
#특성곱 확장 후 LSTAT와 LSTAT 특성을 제곱 후 학습하고 예측
#특성곱 적용한 새로운 컬럼 생성하기
# X_train['LSTAT x LSTAT'] = X_train['LSTAT'] **2
X_train['LSTAT_square'] = X_train['LSTAT'] * X_train['LSTAT']
#모델링
lr_model2 = LinearRegression()
lr_model2.fit(X_train[['LSTAT', 'LSTAT_square']], y_train)
#모델 학습
pre2 = lr_model2.predict(X_train[['LSTAT', 'LSTAT_square']])
#산점도 그래프 그리기
#.scatter(문제 데이터, 답지 데이터)
plt.scatter(X_train[['LSTAT']], y_train) # scatter 산점도 그려주는 함수, 실제 답
plt.scatter(X_train[['LSTAT']], pre2, color='red') # scatter 산점도 그려주는 함수, 예측 답
plt.xlabel('LSTAT_square')
plt.ylabel('MEDV')
plt.show()

- test 데이터에 LSTAT 특성 곱 적용하고 학습/평가하기
#테스트 데이터 중 LSTAT 특성만 제곱하여 특성제곱 전후 비교
X_test['LSTAT_square']=X_test['LSTAT'] * X_test['LSTAT']
#모델링
lr_model3=LinearRegression()
#모델 학습
lr_model3.fit(X_train, y_train)
lr_model3.score(X_test, y_test)
#일반모델 0.7085045269202357
2)RM 컬럼 특성곱 적용하기
- train 데이터 RM 컬럼 특성곱 적용하고 학습/예측하기
#특성곱 확장
#RM와 RM특성을 제곱 후 학습하고 예측
#새로운 컬럼
# X_train['LSTAT x LSTAT'] = X_train['LSTAT'] **2
X_train['RM_square'] = X_train['RM'] * X_train['RM']
#모델링
lr_model11 = LinearRegression()
#모델 학습
lr_model11.fit(X_train[['RM', 'RM_square']], y_train)
#모델 예측
pre11 = lr_model11.predict(X_train[['RM', 'RM_square']])
#산점도 그래프 그리기
#.scatter(문제 데이터, 답지 데이터)
plt.scatter(X_train[['RM']], y_train) # scatter 산점도 그려주는 함수, 실제 답
plt.scatter(X_train[['RM']], pre11, color='red') # scatter 산점도 그려주는 함수, 예측 답
plt.show()
- test 데이터 RM 컬럼 특성곱 적용하고 학습/평가하기
#테스트 데이터 중 RM 특성만 제곱하여 특성제곱 전후 비교
X_test['RM_square']=X_test['RM'] * X_test['RM']
#모델링
lr_model3=LinearRegression()
#모델 학습
lr_model3.fit(X_train, y_train)
lr_model3.score(X_test, y_test)
#일반모델 0.7085045269202357
#LSTAT 제곱: 0.7752718351923247
3)모든 컬럼에 특성곱 적용하기
- 원본데이터 복제
#데이터 복제
extend_X_train=X_train.copy()
extend_X_test=X_test.copy()
- 경고창 무시하기
#경고창 무시하기
import warnings
warnings.filterwarnings('ignore')
- train 데이터 모든 컬럼 특성곱 적용하기
#반복문을 이용하여 train 데이터 모든 컬럼 특성곱 적용하기
for col1 in X_train.columns: #13번 반복
for col2 in X_train.columns:
#특성곱 컬럼 추가
extend_X_train[col1+ 'x'+col2]=X_train[col1]* X_train[col2]
- text 데이터 모든 컬럼 특성곱 적용하기
#반복문을 이용하여 test 데이터 모든 컬럼 특성곱 적용하기
for col1 in X_test.columns: #13번 반복
for col2 in X_test.columns:
#특성곱 컬럼 추가
extend_X_test[col1+ 'x'+col2]=X_test[col1]* X_test[col2]
- 모델 학습/평가
#모델 생성
lr_model22=LinearRegression()
#모델 학습
lr_model22.fit(extend_X_train, y_train)
lr_model22.score(extend_X_test, y_test)
#train 데이터 score 출력
lr_model22.score(extend_X_train, y_train)
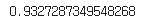
#test 데이터 score출력
lr_model22.score(extend_X_test, y_test)

-test 데이터보다 train 데이터의 score가 더 높음=>과적합 발생
-원인: 특성곱으로 특성이 너무 많아짐
-해결방법: 모델의 정규화
8. 모델 정규화
#규제 모델 import
from sklearn.linear_model import Lasso # L1
from sklearn.linear_model import Ridge # L2
from sklearn.linear_model import ElasticNet # ElasticNet
1)L1(Lasso) 모델
#L1 모델 생성
#alpha값으로 규제 강도 설정
#alpha 값이 높아지면 규제 강도가 커지고 과대적합 위험성 감소, 오차 증가
lasso_model=Lasso(alpha=10)
#L1 모델 학습
lasso_model.fit(extend_X_train, y_train)
#가중치->.coef_
print('가중치: ', lasso_model.coef_) #가중치(w)
#Lasso는 필요없는 특성의 가중치(w) 값을 0으로 바꾸기 때문에
0이 아닌 가중치(w) 값의 개수를 구하면 학습에 사용된 특성의 개수를 알 수 있음
#점수: np.sum(lasso_model.coef_!=0)
print(f'사용되는 특성의 개수: {np.sum(lasso_model.coef_!=0)}')

전체 182개 컬럼 중 연관성이 높은 48개 컬럼만 사용
#L1 모델 예측
#과대적합 제어정도를 확인하기 위해 train, test데이터 각각 예측
pre_lasso_train= lasso_model.predict(extend_X_train)
pre_lasso_test= lasso_model.predict(extend_X_test)
#회귀 평가지표(MSE, RMSE)
#평가지표가 0에 가까울수록 좋은 모델
#MSE: mean_squared_error(예측답지, 실제 답지)
#잔차: train MSE에서 test의 MSE를 뺀 값
train_mes_lasso=mean_squared_error(pre_lasso_train, y_train)
test_mes_lasso=mean_squared_error(pre_lasso_test, y_test)
#MSE 값 확인
print(f'train 데이터 MSE 값: {train_mes_lasso}')
print(f'test 데이터 MSE 값: {test_mes_lasso}')
print(f'MES 잔차: {train_mes_lasso-test_mes_lasso}')
#RMSE 값 확인: np.sqrt(MSE)
print(f'train 데이터 RMSE 값: {np.sqrt(train_mes_lasso)}')
print(f'test 데이터 RMSE 값: {np.sqrt(test_mes_lasso)}')
print(f'RMSE 잔차: {np.sqrt(train_mes_lasso)-np.sqrt(test_mes_lasso)}')
#lasso model train score
np.round(lasso_model.score(extend_X_train, y_train),2)
#lasso model test score
np.round(lasso_model.score(extend_X_test, y_test),2)
#일반모델 성능 점수
-lr 모델 extend X_train의 score: 0.93
-lr 모델 extend X_test의 score: 0.87
->잔차: 6
#lasso 모델 성능점수
-lasso model train score: 0.86
-lasso model test score 0.82
->잔차 4
#규제모델 사용 후 과적합 감소(잔차 6→4), 예측률은 감소(0.87→0.82)
2)L2(Ridge) 모델
#Ridge 모델 생성
ridge_model=Ridge(alpha=10)
#학습
ridge_model.fit(extend_X_train, y_train)
#가중치->.coef_
print('가중치: ', ridge_model.coef_)
#점수: np.sum(ridge_model.coef_!=0)
print(f'사용되는 특성의 개수: {np.sum(ridge_model.coef_!=0)}')

#L2모델은 모든 특성을 골고루 규제하므로 모든 특성을 사용함
#ridge 모델 예측
#과대적합 제어 정도를 확인하기 위해 train, test데이터 각각 예측
pre_ridge_train= ridge_model.predict(extend_X_train)
pre_ridge_test= ridge_model.predict(extend_X_test)
#회귀 평가지표(MSE, RMSE)
#평가지표가 0에 가까울수록 좋은 모델
#MSE: mean_squared_error(예측답지, 실제 답지)
#잔차: train MSE에서 test의 MSE를 뺀 값
train_mes_ridge=mean_squared_error(pre_lasso_train, y_train)
test_mes_ridge=mean_squared_error(pre_lasso_test, y_test)
#MSE 값 확인
print(f'train 데이터 MSE 값: {train_mes_ridge}')
print(f'test 데이터 MSE 값: {test_mes_ridge}')
print(f'MES 잔차: {train_mes_ridge-test_mes_ridge}')
#RMSE 값 확인: np.sqrt(MSE)
print(f'train 데이터 RMSE 값: {np.sqrt(train_mes_ridge)}')
print(f'test 데이터 RMSE 값: {np.sqrt(test_mes_ridge)}')
print(f'RMSE 잔차: {np.sqrt(train_mes_ridge)-np.sqrt(test_mes_ridge)}')
#ridge model train score
np.round(ridge_model.score(extend_X_train, y_train),2)
#ridge model test score
np.round(ridge_model.score(extend_X_test, y_test),2)
# 일반모델 성능 점수
-lr 모델 extend X_test의 score: 0.87
-lr 모델 extend X_train의 score: 0.93
->잔차: 6
#lasso 모델 성능점수
-lasso model train score: 0.86
-lasso model test score 0.82
->잔차 4
#ridge 모델 성능점수
-ridge model train score: 0.92
-ridge model test score: 0.84
->잔차: 8
#Ridge 모델은 모델 정규화하기 전보다 과대적합이 오히려 더 증가함
9. 하이퍼 파라미터 튜닝
1)Lasso 모델 하이퍼 파라미터 튜닝
- 반복문을 사용하여 하이퍼 파라미터 튜닝
#lasso 모델 하이퍼 파라미터 튜닝
#alpha 값에 따라 RMSE 계산값을 빈 리스트에 담기
#alpha값 리스트
alpha_list=[0.001, 0.01, 0.1, 1, 10,100,1000]
#RMSE 결과값 저장할 리스트 생성
lasso_train_list=[]
lasso_test_list=[]
#반복문을 사용하여 lasso 모델 하이퍼 파라미터 튜닝
for i in alpha_list: #8번
#모델 생성
lasso_model=Lasso(alpha=i)
#모델 학습
lasso_model.fit(extend_X_train, y_train)
#모델 예측(train)
lasso_train_pre=lasso_model.predict(extend_X_train)
#RMSE 계산(train)
lasso_train_rmse=np.sqrt(mean_squared_error(lasso_train_pre, y_train))
#lasso_train_list에 RMSE 값 넣기
lasso_train_list.append(lasso_train_rmse)
#모델 예측(test)
lasso_test_pre=lasso_model.predict(extend_X_test)
#RMSE 계산(test)
lasso_test_rmse=np.sqrt(mean_squared_error(lasso_test_pre, y_test))
#lasso_test_list에 RMSE 값 넣기
lasso_test_list.append(lasso_test_rmse)
- 하이퍼 파라미터 적용한 데이터를 시각화
#lasso 모델의 train/test의 RMSE 값을 그래프로 표현
import matplotlib.pyplot as plt
plt.figure(figsize=(10,7))
plt.plot(lasso_train_list, label='train') #train 그래프
plt.plot(lasso_test_list, label='test') #test 그래프
plt.title('Lasso Model: alpha / RMSE Graph') #그래프 제목
plt.xlabel('alpha') #x축 라벨
plt.ylabel('RMSE') #y축 라벨
plt.legend()
plt.grid() #격자 무늬
plt.show()
2)Ridge 모델 하이퍼 파라미터 튜닝
- 반복문을 사용하여 하이퍼 파라미터 튜닝
#Ridge 모델 하이퍼 파라미터 튜닝
#alpha 값에 따라 RMSE 계산값을 빈 리스트에 담기
#alpha값 리스트
alpha_list=[0.001, 0.01, 0.1, 1, 10,100,1000]
#RMSE 결과값 저장할 리스트 생성
ridge_train_list=[]
ridge_test_list=[]
#반복문을 사용하여 Ridge 모델 하이퍼 파라미터 튜닝
for i in alpha_list: #8번
#모델 생성
ridge_model=Ridge(alpha=i)
#모델 학습
ridge_model.fit(extend_X_train, y_train)
#모델 예측(train)
ridge_train_pre=ridge_model.predict(extend_X_train)
#RMSE 계산(train)
ridge_train_rmse=np.sqrt(mean_squared_error(ridge_train_pre, y_train))
#ridge_train_list에 RMSE 값 넣기
ridge_train_list.append(ridge_train_rmse)
#모델 예측(test)
ridge_test_pre=ridge_model.predict(extend_X_test)
#RMSE 계산(test)
ridge_test_rmse=np.sqrt(mean_squared_error(ridge_test_pre, y_test))
#ridge_test_list에 RMSE 값 넣기
ridge_test_list.append(ridge_test_rmse)
- 하이퍼 파라미터 적용한 데이터를 시각화
#Ridge 모델의 train/test의 RMSE 값을 그래프로 표현
import matplotlib.pyplot as plt
plt.figure(figsize=(10,7))
plt.plot(ridge_train_list, label='train') #train 그래프
plt.plot(ridge_test_list, label='test') #test 그래프
plt.title('Ridge Model: alpha / RMSE Graph') #그래프 제목
plt.xlabel('alpha') #x축 라벨
plt.ylabel('RMSE') #y축 라벨
plt.legend()
plt.grid()
plt.show()
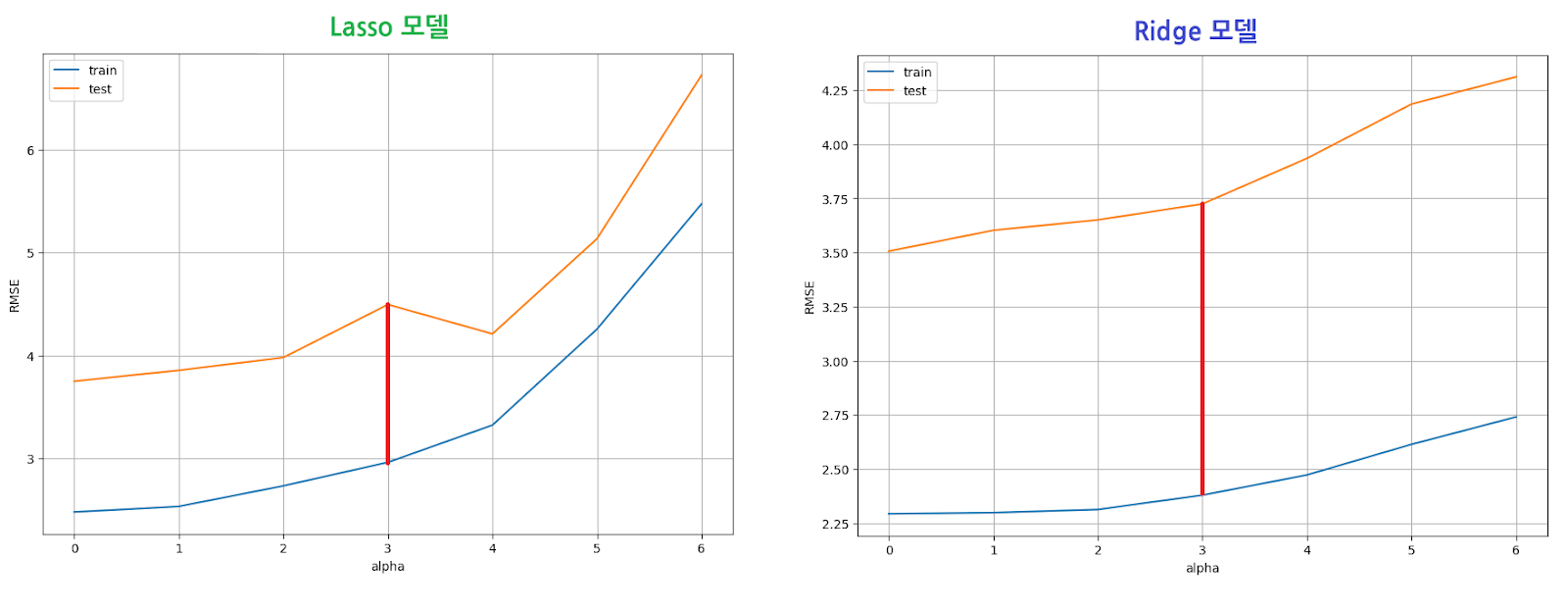
#보스턴 주택 가격 데이터 하이퍼파라미터 튜닝 후
#Lasso모델이 Ridge모델보다 train 데이터와 test 데이터의 RMSE값의 차이가 적다->Lasso 모델이 과대적합 제어에 더 유리하다
3)ElasticNet 모델 하이퍼 파라미터 튜닝
- alpha: 규제의 강도
- l1_ratio: L1, L2 규제 비율
예)l1_ratio=0.5(L1 : L2=5:5) /0(L2 규제만 사용)/1(L1 규제만 사용)
# ElasticNet 모델 불러오기
from sklearn.linear_model import ElasticNet
#ElasticNet 모델 생성
#alpha: 규제의 강도
#l1_ratio: L1, L2 규제 비율
ela_model=ElasticNet(alpha=10, l1_ratio=0.5)
#ElasticNet 모델 학습
ela_model.fit(extend_X_train, y_train)
#ElasticNet 예측
ela_train_pre=ela_model.predict(extend_X_train)
ela_test_pre=ela_model.predict(extend_X_test)
#규제모델 적용 후 MSE, RMSE 계산
train_mse_ela=mean_squared_error(ela_train_pre, y_train)
test_mse_ela=mean_squared_error(ela_test_pre, y_test)
#MSE 값 확인
print(f'train 데이터 MSE 값: {train_mse_ela}')
print(f'test 데이터 MSE 값: {test_mse_ela}')
print(f'MES 잔차: {train_mse_ela-test_mse_ela}')
#RMSE 값 확인: np.sqrt(MSE)
print(f'train 데이터 RMSE 값: {np.sqrt(train_mse_ela)}')
print(f'test 데이터 RMSE 값: {np.sqrt(test_mse_ela)}')
print(f'RMSE 잔차: {np.sqrt(train_mse_ela)-np.sqrt(test_mse_ela)}')
#ElasticNet train 데이터 성능점수
np.round(ela_model.score(extend_X_train, y_train),2)
#ElasticNet test 데이터 성능점수
np.round(ela_model.score(extend_X_test, y_test),2)
## 일반모델 성능 점수
#lr 모델 extend X_test의 score: 0.87
#lr 모델 extend X_train의 score: 0.93
#->잔차: 6
## lasso 모델 성능점수
#lasso model train score: 0.86
#lasso model test score 0.82
#->잔차 4
## ridge 모델 성능점수
#ridge model train score: 0.92
#ridge model test score: 0.84
#->잔차: 8
## ElasticNet 모델 성능점수
#ElasticNet model train score: 0.87
#ElasticNet model train score: 0.81
#->잔차: 6
'코딩 > 머신러닝' 카테고리의 다른 글
| [ML]13. 자연어 처리 (0) | 2023.09.06 |
|---|---|
| [ML]12. 로지스틱 회귀모델 (0) | 2023.09.01 |
| [ML]10. 선형회귀모델 (0) | 2023.08.30 |
| [ML]9. 분류평가지표 (0) | 2023.08.29 |
| [ML]8. 타이타닉호 생존자 예측 모델 (0) | 2023.08.25 |