머신러닝 09_분류평가지표
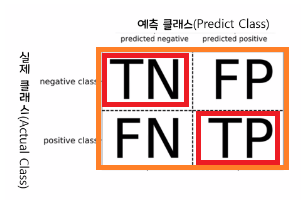
- 오차행렬(Confusion_matrix)

- TN(True Negative): 실제 False인 정답을 False로 예측(정답)
- FN(False Nagative): 실제 True인 정답을 False로 예측(오답)
- FP(False Positive): 실제 False인 정답을 True로 예측(오답)
- TP(True Positive): 실제 True인 정답을 True로 예측(정답)
1)정확도(Accuracy): 전체 데이터 중에서 실제 정답을 정확히 맞춘 비율
- 불균형한 데이터가 있을 경우 정확도로 성능을 평가하는 것이 문제가 됨
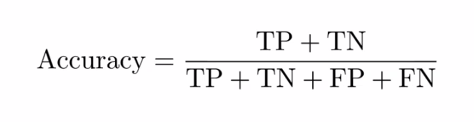
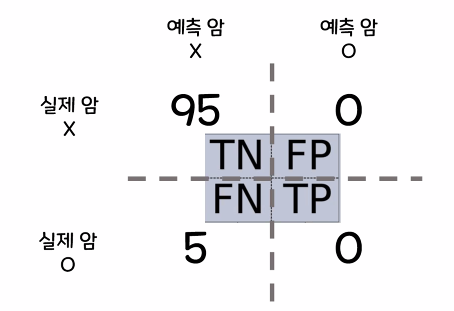
→정확도는 95%지만 실제 암환자를 한 명도 예측하지 못함
2)재현율(Recall): 실제 정답 중에 정확히 예측한 비율



→같은 결과에서 정확도는 95%지만 재현율은 0%로 암 진단 예측의 부정확함을 알 수 있음
3)정밀도(Precision): 예측한 데이터 중 실제로 정답인 비율

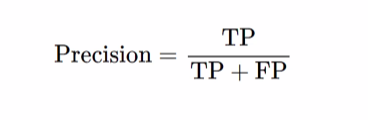

→암환자로 예측한 사람 중 실제 암인 사람 5명을 잘 맞춤
| 구분 | 재현율 선호 | 정밀도 선호 |
| 상황 | 실제 positive인 데이터를 Negative로 잘못 예측하면 업무상 큰 영향을 미침 | 실제 Negative인 데이터를 positive로 잘못 예측하면 업무상 큰 영향을 미침 |
| 예시 | 암 진단, 금융사기 판별, 도둑 판별 | 스팸메일, 안전영상 |
4)F1-score: 정밀도와 재현율의 조화평균

2. ROC curve: 민감도와 특이도를 사용해서 모델의 성능을 평가


- TRR이 1에 가까울 수록 좋은 모델
- ROC 그래프의 밑부분 면적(AUC)이 넓을 수록 좋은 모형으로 평가
- ROC 그래프에서 이상적으로 완벽히 분류한 모형의 x, y 값 = (0,1)
[타이타닉 생존예측 모델 평가]
7. 데이터 학습 및 평가
1)train, validation, test 데이터로 분할
- 평가지표를 사용하기 위해 실제 정답데이터가 필요함
- 검증용 정답으로 실제 정답 대체
#학습용 데이터를 학습용과 검증용 데이터로 분할
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val=train_test_split(X_train, y_train,
test_size=0.2, random_state=42)
#학습용 데이터를 학습용과 검증용 데이터로 분할
from sklearn.model_selection import train_test_split
X_tr, X_val, y_tr, y_val=train_test_split(X_train, y_train,
test_size=0.2, random_state=42)
#새로 분할한 학습용 데이터로 학습
model.fit(X_tr, y_tr)
#검증용 데이터로 예측
y_pred=model.predict(X_val)
2)분류평가지표
- 정확도(accuracy)
- 재현율(recall)
- 정밀도(precision)
- F1 score
accuracy = accuracy_score(y_val, y_pred) #정확도
precision = precision_score(y_val, y_pred) #정밀도
recall = recall_score(y_val, y_pred ) #재현율
f1 = f1_score(y_val, y_pred) #F1 점수
conf_matrix = confusion_matrix(y_val, y_pred) #오차행렬

- 분류모델 결과보고서로 분류평가지표 한꺼번에 확인
#분류 평가지표 보고서 출력(sklearn에서만 사용가능)
class_names=breast_cancer.target_names
#classification_report(실제 정답, 예측정답, 타겟이름)
report=classification_report(y_test,logi_pre,target_names=class_names)
print('분류모델 평가지표 보고서\n', report)

3)ROC curve
#검증용 데이터로 예측확률 구하기 (.predict_proba)
y_pred_prob = model.predict_proba(X_val)[:, 1]
# 양성 클래스(1)의 예측 확률 사용
# ROC Curve 및 AUC 계산
fpr, tpr, thresholds = roc_curve(y_val, y_pred_prob)
roc_auc = roc_auc_score(y_val, y_pred_prob)
# ROC Curve 그리기
plt.figure()
plt.plot(fpr, tpr, label='ROC Curve (AUC = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc="lower right")
plt.show()

'코딩 > 머신러닝' 카테고리의 다른 글
| [ML]11. 모델 정규화 (0) | 2023.08.31 |
|---|---|
| [ML]10. 선형회귀모델 (0) | 2023.08.30 |
| [ML]8. 타이타닉호 생존자 예측 모델 (0) | 2023.08.25 |
| [ML]7. 앙상블 모델 (0) | 2023.08.18 |
| [ML]6. Decision Tree 모델 (0) | 2023.08.17 |