딥러닝_06_CNN
- DNN(Deep Neural Network); 은닉층을 늘려서 학습을 반복하여 최적의 해 도출
-대표적인 알고리즘: CNN, RNN, LSTM, GRU 등
2. CNN(Convolution Neural Network): 이미지 데이터의 특성을 추출하는 알고리즘
- 과대적합, 기울기 소실문제, 학습시간이 오래 걸리는 문제 해결
- 기존의 방식: 이미지 패턴의 위치 기반으로 이미지 데이터 학습

- CNN 방식: 이미지 데이터의 특징 중 중요한 특성을 추출하여 학습

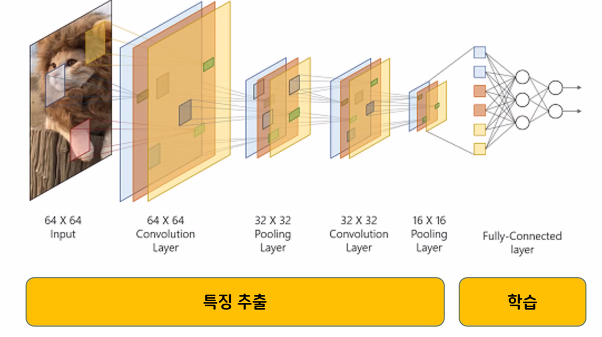
3. CNN 과정: 이미지→[특성 추출→이미지 크기 줄이기]*반복→여러 작은 특성 이미지 추출→학습→예측
- Convolution: filter 연산, 이미지의 특징을 찾기 위해 필터링 수행
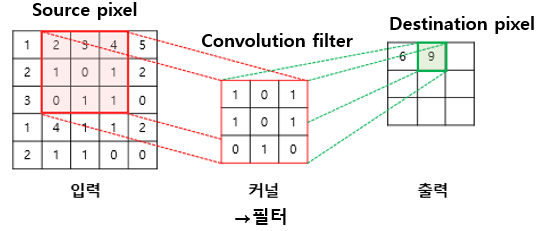



*필터 시뮬레이터 https://setosa.io/ev/image-kernels/
4. CNN 오차 역전파
- CNN 적용한 신경망 모델 역전파 과정

- CNN층 역전파 과정

5. CNN의 단점
- 학습을 진행하면서 특성 이미지의 크기가 줄어들어 이미지 손실
- 가장자리에 있는 이미지는 특징 추출이 적게 이루어져 가중치가 낮아짐
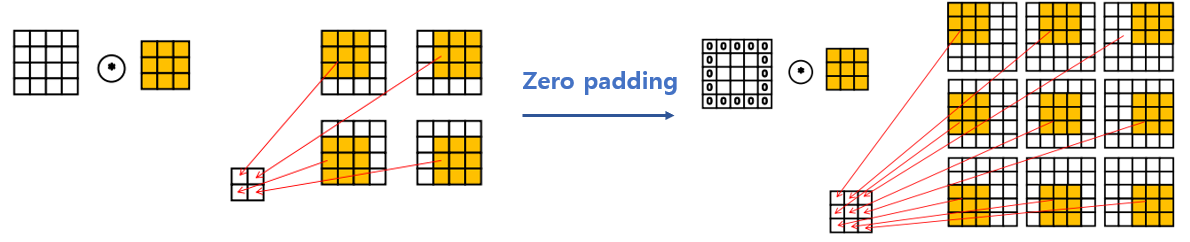
6. Padding: CNN의 단점을 보완하기 위해 이미지 크기를 유지하는 작업
- zero padding: convolution을 적용하면 이미지 크기가 줄어들기 때문에 이미지 크기를 유지하기 위해 convolution 전에 테두리를 0으로 채우는 작업
7. 축소샘플링
1)Stride: 입력데이터에 필터를 적용할 때 이동할 간격 조절. 축소샘플링 기법
*stride 값은 필터의 크기보다 작아야 함

2)Pooling(Subsampling): 처리할 데이터의 크기를 줄이는 작업, 축소샘플링 기법
- Max-Pooling: 최대값을 대표값으로 설정
- Average-Pooling: 평균값을 대표값으로 설정
- L2-norm-Pooling: L2 규제에 의한 값을 대표값으로 설정

8. CNN층 파라미터: CNN층은 Conv2D(2~3개)+MaxPooling2D(1개) 한 쌍으로 구성
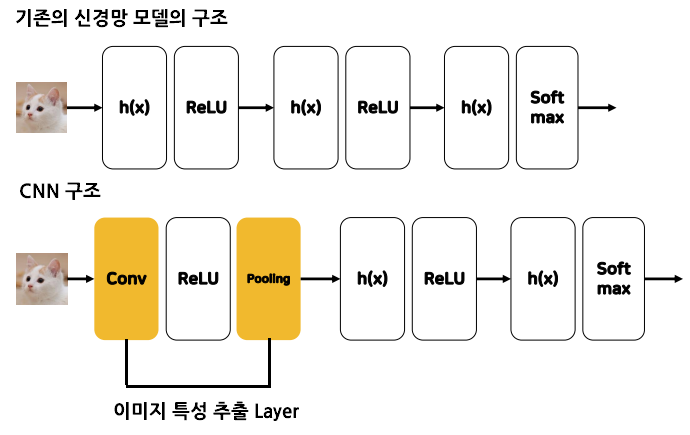
1) Conv2D: 이미지의 중요한 특징을 추출

- filters: Convolution 필터의 수
- kernel_size: Convolution 커널의 행, 열(홀수로 지정)
- padding: 경계의 처리방법
-valid: 유효한 영역만 출력, 출력이미지 크기<입력이미지 크기
-same: 출력이미지 크기=입력이미지 크기
- input_shape: 샘플 수를 제외한 입력 형태(행, 열, 채널 수)로 정의
-채널의 수: 흑백영상(1), 컬러(3)
- activation: 활성화 함수(relu, sigmoid, softmax, linear)
- stride: stride 크기 지정(행, 열)
2)MaxPooling: 이미지의 중요한 특징 외에 특징들을 제거
- pool_size: max pooling 크기 지정(행, 열)
- stride: stride 크기 지정(행, 열)
3)Flatten: 다차원 구조를 1차원 구조로 변경하는 함수(cnn층을 분류기에 적용하기 위해)
[손글씨 데이터 CNN 적용]
- 데이터 불러오기
#손글씨 데이터 불러오기(keras 제공)
from tensorflow.keras.datasets import mnist
#학습용/테스트용 데이터, 문제/정답데이터 구분된 상태
(X_train, y_train), (X_test, y_test)=mnist.load_data()
#데이터 크기 확인
X_train.shape, X_test.shape
#정답데이터 라벨이름 확인
import pandas as pd
print(pd.Series(y_train).unique())
print(pd.Series(y_test).unique())
2. 데이터 분할
#훈련 데이터 6000개
X_train=X_train[:6000, :]
y_train=y_train[:6000]
#테스트 데이터 1000개
X_test=X_test[:1000, :]
y_test=X_test[:1000]
X_train.shape, X_test.shape
3. 데이터 전처리
- 문제데이터 색상 차원 추가
#색상 차원 추가: 흑백은 1, 컬러는 3
X_train=X_train.reshape(6000,28,28, 1)
X_test=X_test.reshape(1000,28,28, 1)
- 정답 데이터 one-hot-encoding
#정답 데이터 one-hot-Encoding
#to_categorical: 라벨 인코딩이 되어있는 경우만 사용가능
from tensorflow.keras.utils import to_categorical
y_train_en=to_categorical(y_train)
y_test_en=to_categorical(y_test)
print(X_train.shape, y_train_en.shape)
print(X_test.shape, y_train_en.shape)
4. CNN 모델 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten
# Conv2D, MaxPolling2D->한 쌍의 convolution
# Conv2D: 이미지에서 특성 추출하는 기능
# MaxPolling2D: 특성 이미지를 축소하는 기능(전체 속도의 60% 차지, 속도 느림)
# Flatten: 다차원 데이터를 1차원 데이터로 변환(Dense 입력)
model1=Sequential()
#특성 추출기(CNN)
#파라미터: filters(필터의 개수), kernel_size(필터의 크기), input_shape(입력데이터 크기)
model1.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=(28,28, 1), activation='relu'))#입력층
model1.add(Conv2D(filters=64, kernel_size=(3,3), activation='relu'))
#파라미터: pool_size: 이미지 축소 크기
model1.add(MaxPooling2D(pool_size=(2,2)))
#Flatten: 특성 추출기와 분류기 연결하기 위해 1차원 변환
model1.add(Flatten())
#Flatten층과 DNN층의 파라미터 수의 차이가 크면 과대적합이 발생할 위험
#분류기(DNN)
model1.add(Dense(units=128, activation='relu'))
model1.add(Dense(units=10, activation='softmax')) #출력층
model1.summary()

5. 모델 학습방법 및 평가방법 설정
#모델 학습방법 및 평가방법 설정(다중분류)
from tensorflow.keras.optimizers import Adam
model1.compile(loss='categorical_crossentropy',
optimizer=Adam(learning_rate=0.01),
metrics=['accuracy'])
6. 모델 학습: 모델 저장, 조기학습중단
#callback 불러오기
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
#best 모델 저장
#드라이브 마운트->경로설정
model_path='/content/drive/MyDrive/Colab Notebooks/DeepLearning/data/digit_cnn/cnn_{epoch:2d}_{val_accuracy:0.2f}.hdf5'
mckp=ModelCheckpoint(filepath=model_path, #저장경로
verbose=1, #데이터 저장로그 출력
save_best_only=True, #모델의 성능이 최고점을 갱신할 때 저장
monitor='val_accuracy') #최고점의 기준
#조기학습 중단
early=EarlyStopping(monitor='val_accuracy', #조기중단의 기준
verbose=1, #로그 출력
patience=10 )#조기중단을 위해 모델성능 개선을 기다리는 최대 횟수
#best 모델과 조기학습중단의 monitor값은 동일하게 하는 것이 바람직함
#모델 학습
h1=model1.fit(X_train, y_train_en, validation_split=0.2,
epochs=100, batch_size=32,
callbacks=[mckp, early]) #callback 함수 사용
#시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
plt.plot(h1.history['accuracy'], label='train_acc')
plt.plot(h1.history['val_accuracy'], label='val_acc')
plt.legend()
plt.show()
7. 모델 성능 개선(과대적합 제어): Dropout
- Dropout: 층마다 사용하는 노드(퍼셉트론)의 비율을 조정하는 것, 학습과정에서 신경망의 일부를 사용하지 않는 방법
1)신경망 구조 설계: Dropout 설정(분류기와 출력층 사이)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten
from tensorflow.keras.layers import Dropout
#뼈대
model2=Sequential()
#CNN층
model2.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=(28,28,1), padding='same', activation='relu'))
model2.add(Conv2D(filters=64, kernel_size=(3,3), activation='relu'))
#파라미터: pool_size: 이미지 축소 크기
model2.add(MaxPooling2D(pool_size=(2,2)))
#특성 추출기와 분류기 연결하기 위해 1차원 변환
model2.add(Flatten())
#Flatten층과 DNN층의 파라미터 수의 차이가 크면 과대적합이 발생할 위험
#분류기(DNN)
model2.add(Dense(units=128, activation='relu'))
#Dropout 설정
model2.add(Dropout(0.5))
#출력층
model2.add(Dense(units=10, activation='softmax'))
model2.summary()
2)모델 학습 및 평가방법 설정
#모델 학습방법 및 평가방법 설정(다중분류)
from tensorflow.keras.optimizers import Adam
model2.compile(loss='categorical_crossentropy',
optimizer=Adam(learning_rate=0.01),
metrics=['accuracy']
)
3)모델 학습
- best 모델 저장
#best 모델 저장
#드라이브 마운트->경로설정
model_path='/content/drive/MyDrive/Colab Notebooks/DeepLearning/data/digit_cnn/cnn_{epoch:2d}_{val_accuracy:0.2f}.hdf5'
mckp=ModelCheckpoint(filepath=model_path, #저장경로
verbose=1, #데이터 저장로그 출력
save_best_only=True, #모델의 성능이 최고점을 갱신할 때마다 저장
monitor='val_accuracy' #최고점의 기준
)
- 조기학습 중단
#조기학습 중단
early=EarlyStopping(monitor='val_accuracy', #조기중단의 기준
verbose=1, #로그 출력
patience=10 #조기중단을 위해 모델성능 개선을 기다리는 최대 횟수
)
#best 모델과 조기학습중단의 monitor값은 동일하게 하는 것이 바람직함
- 모델 학습
#모델 학습
h2=model2.fit(X_train, y_train_en,
validation_split=0.2,
epochs=100, batch_size=50,
callbacks=[mckp, early] #callback 함수 사용
)
- 시각화
#시각화
import matplotlib.pyplot as plt
plt.figure(figsize=(15,5))
plt.plot(h2.history['accuracy'], label='train_acc')
plt.plot(h2.history['val_accuracy'], label='val_acc')
plt.legend()
plt.show()
4)best 모델로 평가하기
#모델 불러오는 도구
from tensorflow.keras.models import load_model
# 저장된 모델 중 정확도가 가장 높은 모델 불러오기
best_model=load_model("/content/drive/MyDrive/Colab Notebooks/DeepLearning/data/digit_cnn/cnn_11_0.93.hdf5")
#best 모델로 평가하기
best_model.evaluate(X_test, y_test_en)
8. 직접 작성한 손글씨 데이터로 예측해보기
#이미지 처리 라이브러리
import PIL.Image as pimg
- 손글씨 이미지 데이터 불러오기
#직접 작성한 손글씨 데이터 불러오기
#컬러->흑백이미지로 변환: .convert('L')
img=pimg.open('/content/drive/MyDrive/Colab Notebooks/DeepLearning/data/손글씨/0.png').convert('L')
plt.imshow(img, cmap='gray')
- 전처리: 이미지 차원 변경
#이미지 전처리(차원 변경)
#1. 차원변경을 위해 이미지 타입 배열형태로 변환
import numpy as np
img=np.array(img)
img.shape
#2. 차원 변경
test_img=img.reshape(1,28,28,1)
#0~1 사이의 값으로 변경
test_img.astype('float32')/255
test_img.shape
- 모델 예측
#예측(best_model)
best_model.predict(test_img)
'코딩 > 딥러닝' 카테고리의 다른 글
| [DL]8. 소리데이터 분석 (2) | 2023.09.22 |
|---|---|
| [DL]7. 과대적합 제어 및 전이학습 (1) | 2023.09.21 |
| [DL]5. 오차 역전파 (0) | 2023.09.15 |
| [DL]4. 다중분류 (0) | 2023.09.14 |
| [DL]3. 퍼셉트론, 다층퍼셉트론 (0) | 2023.09.11 |