딥러닝_07_과대적합 제어 및 전이학습
[과대적합 제어방법]
- 데이터 확장(증식)
- 기존의 데이터에 원래의 특성을 유지하는 선에서 잡음을 추가하거나 데이터를 변형하여 데이터의 양을 증가시키는 방법
- 데이터의 수가 부족한 경우 간단하게 성능을 개선할 수 있음(과대적합 방지)
1)이미지 데이터 확장방법
- rotation_range(360): 0~360° 회전
- width_shift_range(0.1): 전체에서 10%내외 수평이동
- height_shift_range(0.1): 전체에서 10% 내외 수직이동
-일반적으로 이미지는 수평이동보다 수직이동의 영향을 많이 받으므로 수직이동 값을 작게 설정함
- shear_range(0.5): 0.5 radian 내외 시계 반대방향으로 변형
- zoom_range(0.3): 0.7~1.3배로 축소/확대
- Horizontal_filp(True): 수평방향으로 뒤집기
- Vertical_Flip(True): 수직방향으로 뒤집기
-수직방향으로 뒤집기는 이미지에 영향을 많이 주므로 가능한 하지 않음
2)텍스트 데이터 확장 방법
- 단어생략 예) 나는 등산을 좋아해서 ()에 가는 것을 즐긴다
- 단어교환 예)나는 산을 좋아해서 등산에 가는 것을 즐긴다(산↔등산)
- 단어이동 예)나는 좋아해서 가는 것을 즐긴다 등산을 산에
- 번역 후 역번역 예) 저는 등산을 좋아합니다, 등산하는 것을 좋아합니다(역번역)
- 유사어 대체 예) 나는 산을 선호해서 등산 가는 것을 좋아한다
- 임의삽입 예)나는 등산을 좋아해서 일요일마다 산에 가는 것을 즐긴다
3)데이터 증식의 한계점
- 기존 데이터의 특징을 유지할 수 있는 방법만 가능(데이터 손실할 정도 x)
- 지나치게 사용하면 데이터 왜곡발생 가능, 기존데이터의 수보다 적게 증식해야 함
- 데이터 확보는 쉽게 할 수 있는데 획기적으로 성능이 향상되지 않음
- 기존 데이터가 편향되어있다면 증식데이터도 편향됨
- 데이터 증식하면 반복학습 횟수(epochs)를 더 늘려야 성능이 향상됨!
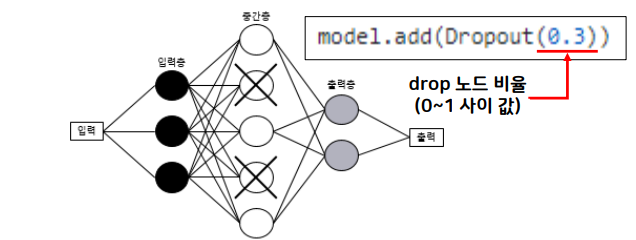
2. Dropout
- 신경망의 각 층에 있는 퍼셉트론의 일부를 설정한 비율만큼 사용하지 않는 것
- 0.5 이상으로 설정하면 설계한 신경망 모델의 특성이 사라지기 때문에 0.5 이하로 설정하는 것이 좋음
- epochs마다 다른 퍼셉트론을 랜덤으로 사용하지 않음
- 층 간 파라미터의 수가 차이 나는 층에 사용(많은 퍼셉트론이 있는 층)
3. BathchNomalization (배치 정규화)
- CNN은 필터를 쓰기 때문에 DNN에 비해 w의 개수가 많아서 복잡함(파라미터가 많음)→파라미터의 분포를 정규화해서 사용하면 성능개선
*정규화: 값들을 평균 0, 분산 1로 만드는 것
<주의점>
- 활성화 함수를 BathchNomalization 다음에 배치
-활성화 함수가 정규화하는 성질이 있어 효과가 감소
- relu 대신 leakyrule 사용
-relu는 정규화한 결과에서 0보다 작은 값을 0으로 만드는 문제(데이터 손실문제)
-relu를 사용하려면 BathchNomalization보다 먼저 사용해야 함
4. GlobalAveragePooling2D
- AveragePooling2D()+Fatten()가 결합된 함수
- 특성 추출기와 분류기 사이에 배치: MaxPooling2D(),Fatten()은 삭제함
<장점>
- MaxPooling2D() 함수를 사용하지 않아 속도 개선
- 자동으로 1차원 데이터로 변환
- 층 간의 파라미터의 수 차이가 줄어듦
[전이학습]
- 전이학습(Transfer Learning): 데이터의 수가 많은 데이터셋을 사용하여 학습한 우수한 사전학습모델을 유사한 다른 데이터를 인식하는데 사용하는 기법
- 사용방법: 우수한 모델에서 CNN(특성추출기) 사용/ 분류기는 새롭게 설계
- 사용하는 이유
-데이터를 확보하기 쉽지 않기 때문에 많은 데이터로 학습한 모델 사용하여 학습효율을 높임
-신경망 설계를 최적화하기 어렵고, 복잡한 모델을 학습시킬 수 있는 하드웨어가 한정되어 있음
- 사전학습모델 이용하는 방법: 특성 추출, 미세조정 방식
1)특성 추출(Feature Extraction): 특성 추출기를 그대로 붙여서 사용, 학습 동결 설정

2)미세 조정(Fine Turning): 특성 추출기를 그대로 붙여서 사용
-분류기 근처의 층만 학습할 수 있도록 학습 동결 해제하고 수행

- 전이학습 모델 구성
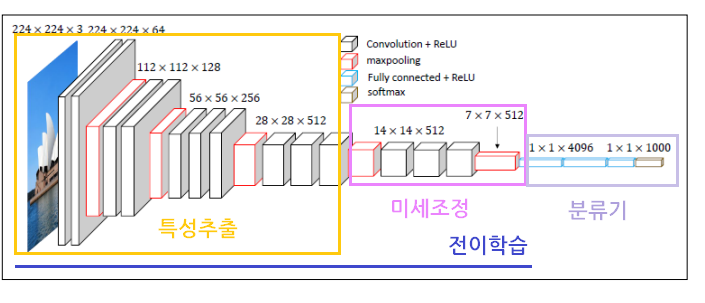
- 데이터 세트 크기와 데이터 세트 유사도에 따른 미세조정 유형

[개, 고양이 분류 실습]
- 개 고양이 분류 데이터 :https://www.kaggle.com/competitions/dogs-vs-cats/data
- 데이터 불러오기
- 작업폴더 이동
#작업 폴더이동
%cd /content/drive/MyDrive/Colab Notebooks/DeepLearning
- 데이터 압축파일 풀기
#데이터 압축파일 풀기
import zipfile
#파일 읽기
zip_file=zipfile.ZipFile("./data/cat_dogs.zip", "r")
#지정한 폴더경로에 압축 풀기
zip_file.extractall("./data")
#압축풀기 종료
zip_file.close()
- 폴더별 데이터 수 확인
#폴더별 데이터 수 확인
import os
#훈련/테스트 폴더경로 변수에 저장
train_dir="./data/cat_dogs/train"
test_dir="./data/cat_dogs/test"
#해당 폴더 경로에 폴더 추가
train_dog_dir=os.path.join(train_dir, "dog")
train_cat_dir=os.path.join(train_dir, "cat")
test_dog_dir=os.path.join(test_dir, "dog")
test_cat_dir=os.path.join(test_dir, "cat")
#각 폴더에 데이터 수 출력
print(f"훈련 데이터(개)의 개수: {len(os.listdir(train_dog_dir))}")
print(f"훈련 데이터(고양이)의 개수: {len(os.listdir(train_cat_dir))}")
print(f"테스트 데이터(개)의 개수: {len(os.listdir(test_dog_dir))}")
print(f"테스트 데이터(고양이)의 개수: {len(os.listdir(test_cat_dir))}")
2. 데이터 전처리: 데이터 스케일링, 폴더 경로, 이미지 개수, 이미지 크기, 라벨링 설정
from tensorflow.keras.preprocessing.image import ImageDataGenerator
#데이터 스케일링
#스케일링 설정
train_gen_set=ImageDataGenerator(rescale=1./255)
test_gen_set=ImageDataGenerator(rescale=1./255)
#데이터 전처리
#이미지 가져올 폴더 설정, 이미지 가져올 개수(batch_size) 설정
#이미지 크기 설정, 라벨링 설정
# from_directory(): 폴더에서 이미지 가져오기
#train 데이터 전처리
train_gen = train_gen_set.flow_from_directory(
train_dir, # 이미지 가져올 폴더 경로
target_size=(150, 150), # 이미지 크기 설정
batch_size=20, # 가져올 이미지의 개수
class_mode='categorical') # 라벨링
#라벨 2개=binary, 라벨 3개 이상=categorical(자동으로 원핫인코딩
#test 데이터 전처리
test_gen = test_gen_set.flow_from_directory(
test_dir, # 폴더 경로
target_size=(150, 150), # 이미지 크기 설정
batch_size=20, # 가져올 이미지의 개수
class_mode='categorical') # 라벨링
#라벨 2개=binary, 라벨 3개 이상=categorical)
#라벨은 폴더명의 알파벳순으로 0부터 부여됨(cat: 0, dog:1)
#라벨링 결과보기
print('훈련용 데이터 라벨', train_gen.class_indices),
print('테스트용 데이터 라벨', test_gen.class_indices)

3. 신경망 구조 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
#뼈대
model1=Sequential()
#특성추출기(2층)
#데이터 전처리 이미지 크기 설정: (150,150), 이미지 종류: 컬러
model1.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=(150,150,3), activation='relu')) #입력층
model1.add(Conv2D(filters=64, kernel_size=(3,3), activation='relu'))
model1.add(MaxPooling2D(pool_size=(2,2)))
model1.add(Conv2D(filters=128, kernel_size=(3,3), activation='relu'))
model1.add(Conv2D(filters=256, kernel_size=(3,3), activation='relu'))
model1.add(MaxPooling2D(pool_size=(2,2)))
#1차원 구조로 변경
model1.add(Flatten())
#분류기
model1.add(Dense(units=128, activation='relu'))
model1.add(Dense(units=2, activation='softmax')) #출력층
#binary 출력결과는 1개->sigmoid
#categorical(자동으로 원핫인코딩) 출력결과 2개->softmax
model1.summary()
4. 학습방법 및 평가방법 설정
model1.compile(loss='binary_crossentropy', optimizer='adam',
metrics=['accuracy'])
5. 학습
#특성이미지+라벨링된 데이터로 학습
#batch_size는 이미 전처리 시 설정되어 있음!
h1=model1.fit(train_gen, epochs=10, validation_data=test_gen)
6. 모델 평가
import matplotlib.pyplot as plt
import numpy as np
ep1=np.arange(1,11)
#정확도 비교
plt.plot(ep1, h1.history['accuracy'], color='red', label='Train')
plt.plot(ep1, h1.history['val_accuracy'], color='blue', label='Validation')
plt.legend()
plt.show()
#오차 비교
plt.plot(ep1, h1.history['loss'], color='red', label='Train')
plt.plot(ep1, h1.history['val_loss'], color='blue', label='Validation')
plt.legend()
plt.show()
[과대적합 제어]
(1)이미지 증식
- 데이터 전처리: 이미지 증식은 train 데이터만 적용해야 함
from tensorflow.keras.preprocessing.image import ImageDataGenerator
#train 데이터 증식
#설정값은 해당 범위의 랜덤값을 적용!
#fill_mode='nearst': 이미지 변형시 깨지는 것을 보상(주변값으로 복원)
train_gen_set=ImageDataGenerator(
#데이터 스케일링
rescale=1./255,
#데이터 증식
rotation_range=20, #회전
width_shift_range=0.2, #좌우이동
height_shift_range=0.1, #상하이동
shear_range=0.1,
zoom_range=0.1,
fill_mode='nearest')
#test 데이터 스케일링
test_gen_set=ImageDataGenerator(rescale=1./255)
#데이터 전처리->from_directory()
#train 데이터 전처리
train_gen = train_gen_set.flow_from_directory(
train_dir, # 이미지 가져올 폴더 경로
target_size=(150, 150), # 이미지 크기 설정
batch_size=20, # 가져올 이미지의 개수
class_mode='categorical') # 라벨링
#test 데이터 전처리
test_gen = test_gen_set.flow_from_directory(
test_dir, # 폴더 경로
target_size=(150, 150), # 이미지 크기 설정
batch_size=20, # 가져올 이미지의 개수
class_mode='categorical') # 라벨링
- 신경망 구조 설계: 이전과 동일함
- 학습방법 및 평가방법 설정: 이전과 동일함
- 학습 및 평가: 이전과 동일함
(2)Dropout
- 데이터 전처리: 이미지 증식하지 않은 데이터스케일링 버전과 동일함
- 신경망 구조 설계: 파라미터 개수의 차이가 많이 나는 곳 중 많은 쪽에 Dropout 배치
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
#뼈대
model3=Sequential()
#특성추출기(3층)
#데이터 전처리 이미지 크기 설정: (150,150), 이미지 종류: 컬러
model3.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=(150,150,3), activation='relu')) #입력층
model3.add(Conv2D(filters=64, kernel_size=(3,3), activation='relu'))
model3.add(MaxPooling2D(pool_size=(2,2)))
model3.add(Conv2D(filters=128, kernel_size=(3,3), activation='relu'))
model3.add(Conv2D(filters=256, kernel_size=(3,3), activation='relu'))
model3.add(MaxPooling2D(pool_size=(2,2)))
#1차원 구조로 변경
model3.add(Flatten())
#분류기
#Dropout 설정: 파라미터 개수의 차이가 많은 곳 중 파라미터의 개수가 많은 층에 위치
model3.add(Dropout(0.5))
model3.add(Dense(units=512, activation='relu'))
model3.add(Dense(units=2, activation='softmax')) #출력층
#binary 출력결과는 1개->sigmoid
#categorical(자동으로 원핫인코딩) 출력결과 2개->softmax
model3.summary()
- 학습방법 및 평가방법 설정: 이전과 동일함
- 학습 및 평가: 이전과 동일함
(3)BathchNomalization
- 신경망 구조 설계: 활성화 함수 전 BathchNomalization 배치
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.layers import BatchNormalization
model4=Sequential()
#특성추출기(2층)
#데이터 전처리 이미지 크기 설정: (150,150), 이미지 종류: 컬러
#1층
model4.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=(150,150,3), activation='relu')) #입력층
#>>BatchNormalization
model4.add(BatchNormalization())
#활성화 함수
model4.add(Conv2D(filters=64, kernel_size=(3,3), activation='relu'))
model4.add(MaxPooling2D(pool_size=(2,2)))
#2층
model4.add(Conv2D(filters=128, kernel_size=(3,3), activation='relu'))
#>>BatchNormalization
model4.add(BatchNormalization())
#활성화 함수
model4.add(Conv2D(filters=256, kernel_size=(3,3), activation='relu'))
model4.add(MaxPooling2D(pool_size=(2,2)))
#1차원 구조로 변경
model4.add(Flatten())
#분류기
#파라미터 개수의 차이가 많이 나는 곳 중 파라미터의 개수가 많은 층에 Dropout 설정
model4.add(Dropout(0.5))
model4.add(Dense(units=512, activation='relu'))
model4.add(Dense(units=2, activation='softmax')) #출력층
#binary 출력결과는 1개->sigmoid
#categorical(자동으로 원핫인코딩) 출력결과 2개->softmax
model4.summary()
- 학습방법 및 평가방법 설정: 이전과 동일함
- 학습 및 평가: 이전과 동일함
(4)GlobalAveragePooling2D
- 신경망 구조 설계: 특성 추출기와 Flatten 사이에 GlobalAveragePooling2D 배치
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.layers import GlobalAveragePooling2D
model5=Sequential()
#특성추출기(2층)
#데이터 전처리 이미지 크기 설정: (150,150), 이미지 종류: 컬러
#1층
model5.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=(150,150,3), activation='relu')) #입력층
model5.add(Conv2D(filters=64, kernel_size=(3,3), activation='relu'))
model5.add(MaxPooling2D(pool_size=(2,2)))
#2층
model5.add(Conv2D(filters=128, kernel_size=(3,3), activation='relu'))
model5.add(Conv2D(filters=256, kernel_size=(3,3), activation='relu'))
#model5.add(MaxPooling2D(pool_size=(2,2)))
#>>GlobalAveragePooling2D<<
model5.add(GlobalAveragePooling2D())
#1차원 구조로 변경
#model4.add(Flatten())
#분류기
model5.add(Dense(units=512, activation='relu'))
model5.add(Dense(units=2, activation='softmax')) #출력층
model5.summary()
- 학습방법 및 평가방법 설정: 이전과 동일함
- 학습 및 평가: 이전과 동일함
[전이학습]
- 특성 추출기 전이학습 수행
# 모델 가져오기(VGG16)
from tensorflow.keras.applications import VGG16
#weights: 어떤 가중치를 가져올 건지 설정(imagenet)
#include_top: 특성추출기만 가져오기(False), 전체데이터(True)
#input_shape: 우리 데이터의 크기
conv_base=VGG16(weights="imagenet", include_top=False,
input_shape=(150,150,3))

- 학습가능한 레이어 개수
print("학습가능한 파라미터 개수: ", len(conv_base.trainable_weights))
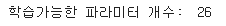
2. 기존 분류기 전이학습 모델(VGG16) 연결하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
#뼈대
model6=Sequential()
#VGG16 특성추출기 연결
model6.add(conv_base)
#flatten
model6.add(Flatten())
#분류기
model6.add(Dropout(0.5))
model6.add(Dense(units=512, activation='relu'))
model6.add(Dense(units=2, activation='softmax')) #출력층
model6.summary()
- 학습 가능한 레이어 수 확인
#학습 가능한 층을 확인
print(f"훈련가능한 레이어 수: {len(model6.trainable_weights)}")
#vgg16 26개+Dense 2개+Dense1 2개

3. VGG 모델 동결: VGG 모델은 학습되지 않도록 설정
#학습동결
conv_base.trainable=False
#학습 가능한 층을 확인
print(f"훈련가능한 레이어 수: {len(model6.trainable_weights)}")
#분류기만 학습이 됨

4. 미세조정(Fine Tuning): 분류기와 근접한 특성추출기 층은 학습하도록 학습동결 해제
#특성추출기 전체 부분 학습 동결 해제
conv_base.trainable=True
#훈련가능 여부 저장
#초기값은 학습이 안 되도록 설정
set_trainable=False
#레이어를 반복하며 분류기와 근접한 특성추출기(block5_conv1)면 동결 해제
for layer in conv_base.layers:
if layer.name=='block5_conv1':
set_trainable=True
if set_trainable:
layer.trainable=True
else:
layer.trainable=False
print(f"훈련 가능한 레이어 수: {len(model6.trainable_weights)}")
#VGG16: 3*(w, b)->6개
#Dense: 2*(w, b)->4개

5. 학습방법 및 평가방법 설정: 이전과 동일함
6. 학습 및 평가: 이전과 동일함
'코딩 > 딥러닝' 카테고리의 다른 글
| [DL]9. 네이버 영화리뷰 감성분석 (0) | 2023.09.27 |
|---|---|
| [DL]8. 소리데이터 분석 (2) | 2023.09.22 |
| [DL]6. CNN (0) | 2023.09.20 |
| [DL]5. 오차 역전파 (0) | 2023.09.15 |
| [DL]4. 다중분류 (0) | 2023.09.14 |