딥러닝_08_소리데이터 분석
[아기울음소리 분류 실습]
- 목표
- librosa 라이브러리를 이용하여 음성처리하는 방법
- 소리 데이터를 직접 데이터로 입력받아서 소리분류하는 방법
- 소리데이터를 MFCC로 변환하여 소리를 분류하는 방법
2. 데이터 불러오기
- 아기 울음소리 데이터셋
-3개의 라벨로 구성(silence, crying, laugh)
-훈련데이터 169개, 테스트 데이터 89개로 구성
- 데이터 압축파일 풀기
#데이터 압축풀기
import zipfile
file="./data/baby_sound/baby_sound.zip"
#파일 읽기
zip_ref=zipfile.ZipFile(file, "r")
#지정한 폴더경로에 압축 풀기
zip_ref.extractall("./baby_sound")
#압축풀기 종료
zip_ref.close()
- 소리데이터 출력하기
#librosa 라이브러리: 오디오 및 음악 신호 처리 라이브러리
import librosa
import librosa.display
import numpy as np
import matplotlib.pyplot as plt
import IPython.display
#데이터 폴더 경로
data_dir="./data/baby_sound/"
#소리데이터 불러와서 출력
#wav: 소리데이터
#sr: sampling rate(초 당 데이터 수)
wav, sr=librosa.load(data_dir+"test_voice.wav")
#소리 정보 출력
print(f"sr: {sr}")
#소리데이터의 구조
print(f"wav의 크기: {wav.shape}")
#총 재생시간
print(f"재생시간: {wav.shape[0]/float(sr)}")
- 소리데이터 재생하기
IPython.display.Audio(data=wav, rate=sr)

3. 소리데이터 시각화
#소리데이터 시각화
plt.plot(wav)
plt.show()
#소리의 진폭(높낮이 변화)를 나타냄
#주파수로 변환해서 소리데이터를 분석함

4. 진폭성분으로 구성된 소리데이터를 주파수 성분(초 당 진동 수)으로 변환
- 사람마다 목소리에 포함된 주파수 성분은 고유함→성대모양이 다르기 때문
- 주파수 성분을 분석하면 사람 인식, 소리분석, 음악분석, 목소리 복원 등 가능
#진폭을 주파수 변환(푸리에 변환)->amplitude_to_db
db=librosa.amplitude_to_db(np.abs(librosa.stft(wav[:2048])))
plt.plot(db.flatten())
plt.show()

5. mel-spectrum: 이미지학습을 위해 소리 데이터를 이미지 데이터로 변환
- mel-spectrum: 사람의 귀에 맞게 데이터를 샘플링한 것
- 사람은 저주파는 잘 듣고, 고주파는 잘 못 들음
- 저주파→세밀하게 샘플링, 고주파→듬성듬성 샘플링

#멜스펙트럼으로 변환
#->librosa.feature.melspectrogram()
#n_mels: mel-spectrum의 수(그래프 세로축의 눈금 수)
S=librosa.feature.melspectrogram(y=wav, sr=sr, n_mels=128)
#시각화를 위해 log사용
log_S=librosa.power_to_db(S, ref=np.max)
plt.figure(figsize=(8,4))
librosa.display.specshow(log_S, sr=sr, x_axis="time", y_axis="mel")
plt.colorbar()
plt.show()
#x축 시간, y축 Mel주파수의 개수
#밝은 색일 수록 Mel주파수의 성분의 개수가 많음
#검정색은 Mel주파수 성분이 없는 것(소리 없음)
#저주파에 Mel주파수의 강도가 높음을 알 수 있음
#그래프가 끊긴 것은 말을 끊어서 말하는 것을 나타냄
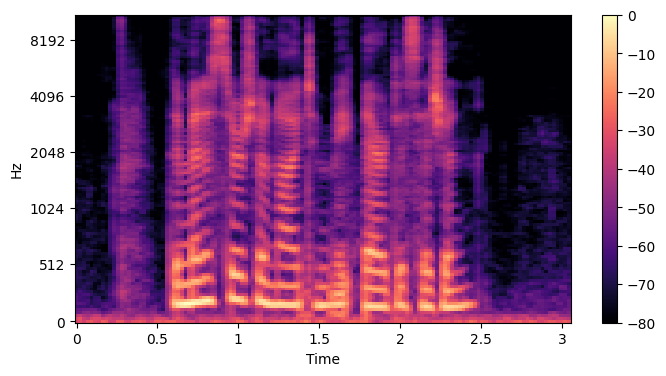
6. MFCC: 멜스펙트럼(아날로그 데이터)을 log를 씌워서 디지털화하는 것
#MFCC
#n_nfcc: mfcc의 구분 수(y축 눈금 수)
mfcc=librosa.feature.mfcc(S=log_S, n_nfcc=13)
plt.figure(figsize=(8,4))
librosa.display.specshow(mfcc)
plt.colorbar()
plt.show()

7. 아기 울음소리 분류
(1)wav 데이터를 Dense층에 직접 입력하여 학습
1)원본 데이터를 학습용 데이터로 변환
-소리 데이터를 신경망 모델에 입력하기 위해 같은 길이로 조절하는 기능

- 1차원 wav 데이터 변환함수: 기준길이에 맞추어 데이터 가로 길이 조절
#1차원 wav 데이터 변환하는 함수
#소리데이터(wav), 기준길이(i)
def pad1d(wav, i):
#소리데이터가 기준길이보다 긴 경우
if wav.shape[0]>i:
return wav[: i] #기준길이만큼 자르기
#소리데이터가 기준길이보다 짧은 경우
else:
#hstack(): 1차원 데이터를 가로방향으로 병합하는 함수
return np.hstack(wav, np.zeros(i-wav.shape[0])) #기준길이에서 부족한 길이만큼 0을 채움
- 2차원 MFCC 데이터 변환함수: 기준열에 맞춰 데이터 열 길이 조절
#2차원 MFCC 데이터 변환하는 함수
#소리데이터(wav), 기준열(i)
def pad2d(wav, i):
#mfcc 데이터(2차원)가 기준열보다 긴 경우
if wav.shape[1]<i:
return wav[:,:i] #열만 기준열만큼 자르기
#mfcc 데이터(2차원)가 기준열보다 짧은 경우
else:
return np.hstack(wav, np.zeros(wav.shape[0], i-wav.shape[1]))
#행은 그대로 두고 열은 기준열에서 부족한 길이만큼 0을 채움
2)학습용/평가용 데이터 만들기
import os
#학습용/평가용 문제/정답 데이터 저장할 리스트
X_train=[]
X_test=[]
y_train=[]
y_test=[]
#소리데이터 폴더 경로
baby_dir="./baby_sound/"
#train 데이터 폴더 경로
train_dir=baby_dir+"train/"
#trian 폴더에 있는 소리 데이터를 함수를 이용하여 학습 데이터로 변환
# os.listdir: 폴더의 파일 읽는 함수
for fname in os.listdir(train_dir):
#label: 파일명을 공백으로 분리하고 0번 인덱스 저장
label=fname.split(" ")[0]
#y_train에 label 저장
y_train.append(label)
#wav 파일을 읽은 후 pad1d 함수를 이용하여 같은 길이로 자르기
wav, sr=librosa.load(train_dir+fname)
pad_x=pad1d(wav, 30000)
#train 데이터에 저장
X_train.append(pad_x)
#test 폴더에 있는 소리 데이터를 함수를 이용하여 학습 데이터로 변환
#test 데이터 폴더 경로
test_dir=baby_dir+"test/"
# os.listdir: 폴더의 파일 읽는 함수
for fname in os.listdir(test_dir):
#label: 파일명을 공백으로 분리하고 0번 인덱스 저장
label=fname.split(" ")[0]
#y_train에 label 저장
y_test.append(label)
#wav 파일을 읽은 후 pad1d 함수를 이용하여 같은 길이로 자르기
wav, sr=librosa.load(test_dir+fname)
pad_x=pad1d(wav, 30000)
#train 데이터에 저장
X_test.append(pad_x)
- 학습용/평가용 데이터 개수 확인
#train/test 데이터 개수 확인
len(X_train), len(X_train[0]), len(X_test), len(X_test[0])

3)데이터 변환
- 가로 형태의 데이터를 세로 형태의 데이터로 변환
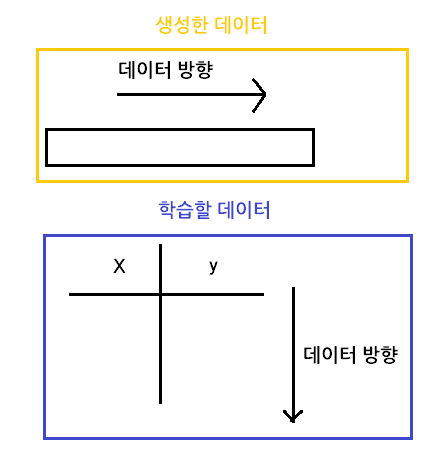
#가로 형태로 되어있는 데이터를 세로 형태로 변환
X_train=np.vstack(X_train)
X_test=np.vstack(X_test)
len(X_train), len(X_train[0]), len(X_test), len(X_test[0])
- 정답 데이터 원핫인코딩
import pandas as pd
y_train_en=pd.get_dummies(y_train)
y_test_en=pd.get_dummies(y_test)
y_train_en.shape, y_test_en.shape
4)신경망 구조 설계

from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
#뼈대
model1=Sequential()
#입력층
model1.add(Dense(units=512, input_dim=30000, activation='relu'))
#은닉층+Dropout으로 과대적합 제어
model1.add(Dropout(0.2))
model1.add(Dense(units=410, activation='relu'))
model1.add(Dropout(0.2))
model1.add(Dense(units=350, activation='relu'))
model1.add(Dropout(0.2))
model1.add(Dense(units=210, activation='relu'))
#출력층
model1.add(Dense(units=3, activation='softmax'))
model1.summary()
5)학습방법 및 평가방법 설정
#학습방법 및 평가방법 설정
model1.compile(loss='categorical_crossentropy',
optimizer='adam',metrics=['accuracy'])
6)학습
#학습
h1=model1.fit(X_train, y_train_en,epochs=20, batch_size=32,
validation_data=(X_test, y_test_en))
#시각화
import matplotlib.pyplot as plt
import numpy as np
ep=np.arange(1,21)
plt.plot(ep, h1.history['accuracy'], color='red', label='train')
plt.plot(ep, h1.history['val_accuracy'], color='blue', label='test')
plt.legend()
plt.show()

7)예측
#예측
pred=model1.predict(X_test)
print(pred[10])
print(y_test_en.iloc[10])
(2)wav 데이터를 Conv1D 층에 직접 입력하여 학습(시계열 분석)
1)차원 추가: CNN층에 데이터 입력하기 위해 차원 추가해야 함
#X_train의 끝에 차원 추가
X_train=np.expand_dims(X_train, -1)
#X_test의 끝에 차원 추가
X_test=np.expand_dims(X_test, -1)
2)신경망 구조 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.layers import Conv1D, MaxPooling1D, GlobalMaxPooling1D
#뼈대
model2=Sequential()
#CNN층
#1차원 데이터
model2.add(Conv1D(filters=64, kernel_size=3, input_shape=(30000,1), activation='relu')) #입력층
model2.add(Conv1D(filters=64, kernel_size=3, activation='relu'))
model2.add(MaxPooling1D(pool_size=3))
model2.add(Conv1D(filters=128, kernel_size=3, activation='relu'))
model2.add(Conv1D(filters=128, kernel_size=3, activation='relu'))
#GlobalMaxPooling1D: MaxPooling1D+Flatten()
#과대적합 제어
model2.add(GlobalMaxPooling1D())
#분류기
model2.add(Dense(units=3, activation='softmax')) #출력층
model2.summary()
3)학습방법 및 평가방법 설정: 이전과 동일함
4)학습: 이전과 동일함
5)예측: 이전과 동일함
6)평가: 이전과 동일함
(3)wav 데이터를 MFCC로 변환하여 Conv2D에 입력하여 학습
1)학습용, 평가용 데이터 만들기: wav→MFCC로 변환
import os
X_train=[]
X_test=[]
y_train=[]
y_test=[]
baby_dir="./baby_sound/"
train_dir=baby_dir+"train/"
#trian 폴더 소리 파일 하나씩 읽어서 학습 데이터로 변환
# os.listdir: 폴더의 파일 읽는 함수
for fname in os.listdir(train_dir):
#label: 파일명을 공백으로 분리하고 0번 인덱스 저장
label=fname.split(" ")[0]
#y_train에 label 저장
y_train.append(label)
#wav 파일 읽기
wav, sr=librosa.load(train_dir+fname)
#wav 파일을 MFCC로 변환하고 pad2d함수로 같은 길이로 조절하기
S=librosa.feature.melspectrogram(y=wav, sr=sr, n_mels=128)
log_S=librosa.power_to_db(S, ref=np.max)
mfcc2 = librosa.feature.mfcc(S=log_S, n_mfcc=20)
pad_x = pad2d(mfcc2, 40)
#train 데이터에 저장
X_train.append(pad_x)
#test 폴더 소리 파일 하나씩 읽어서 학습 데이터로 변환
test_dir=baby_dir+"test/"
# os.listdir: 폴더의 파일 읽는 함수
for fname in os.listdir(test_dir):
#label: 파일명을 공백으로 분리하고 0번 인덱스 저장
label=fname.split(" ")[0]
#y_train에 label 저장
y_test.append(label)
#wav 파일 읽기
wav, sr=librosa.load(test_dir+fname)
#wav 파일을 MFCC로 변환하고 pad2d함수로 같은 길이로 조절하기
S=librosa.feature.melspectrogram(y=wav, sr=sr, n_mels=128)
log_S=librosa.power_to_db(S, ref=np.max)
mfcc2 = librosa.feature.mfcc(S=log_S, n_mfcc=20)
pad_x = pad2d(mfcc2, 40)
#train 데이터에 저장
X_test.append(pad_x)
2)데이터 변환
- 문제데이터 리스트→배열로 변환하기
#리스트->배열
X_train=np.array(X_train)
X_test=np.array(X_test)
X_train.shape, X_test.shape
- 정답 데이터 원핫인코딩
#정답 데이터 원핫인코딩
y_train_en=pd.get_dummies(y_train)
y_train_en=pd.get_dummies(y_train)
y_train_en.shape, y_test_en.shape
- 차원 추가
#차원 추가
X_train=np.expand_dims(X_train, -1)
X_test=np.expand_dims(X_test, -1)
3)신경망 구조 설계
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
from tensorflow.keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2D
#뼈대
model3=Sequential()
#CNN층
#1차원 데이터
model3.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=(20,40,1), activation='relu')) #입력층
#GlobalMaxPooling2D: MaxPooling1D+Flatten()
#과대적합 제어
model3.add(GlobalMaxPooling2D())
#분류기
model3.add(Dense(units=128, activation='relu'))
model3.add(Dense(units=64, activation='relu'))
model3.add(Dense(units=32, activation='relu'))
model3.add(Dense(units=3, activation='softmax')) #출력층
model3.summary()
4)학습방법 및 평가방법 설정: 이전과 동일함
5)학습 및 학습결과 시각화: 이전과 동일함

6)예측: 이전과 동일함
7)평가: 이전과 동일함
'코딩 > 딥러닝' 카테고리의 다른 글
| [DL]10. 객체 탐지 (0) | 2023.10.04 |
|---|---|
| [DL]9. 네이버 영화리뷰 감성분석 (0) | 2023.09.27 |
| [DL]7. 과대적합 제어 및 전이학습 (1) | 2023.09.21 |
| [DL]6. CNN (0) | 2023.09.20 |
| [DL]5. 오차 역전파 (0) | 2023.09.15 |