딥러닝_09_네이버 영화 리뷰 감성 분석
*데이터 다운로드: ratings_train, ratings_test
- 데이터 불러오기
import pandas as pd
train_data=pd.read_table("./data/ratings_train.txt")
test_data=pd.read_table("./data/ratings_test.txt")
2. 결측치 제거
- 결측치 데이터 개수 확인
#결측치 데이터 개수 확인
#True: 결측치, False: 결측치 아님
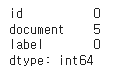
print(train_data.isnull().sum())
#document에 결측치 5개 있음
- 결측치 데이터 확인
#결측치 데이터 확인
train_data.loc[train_data.document.isnull()]

- 결측치 제거
#결측치 제거
#하나의 컬럼이라도 결측치가 있으면 데이터 삭제
train_data=train_data.dropna(how='any')
3. 정규식을 이용하여 한글데이터 추출하기
- 한글과 공백이 아닌 값을 삭제
#한글과 공백이 아닌 값을 삭제
#ㄱ-ㅎ: 자음(ㄱ~ㅎ)
#ㅏ-ㅣ: 모음(ㅏ-ㅣ)
#가-힣: 문자
#띄어쓰기: 공백
#^부정
train_data['document']=train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]", "")
#영문자, 숫자: [a-zA-Z0-9]
- 비어있는 데이터(공백) 확인(≠null)
#비어있는 데이터 확인
train_data.loc[train_data['document']==""]
#비어있는 데이터 삭제하기->비어있지 않은 데이터만 다시 저장하기
#.str.strip(): 공백
#!="": 비어있는 데이터
#비어있는 데이터와 공백이 아닌 데이터만 저장하기
train_data=train_data[train_data['document'].str.strip()!=""]
4. 불용어(StopWord) 처리, 토큰화: Okt 이용하기, 정규화: 어간추출
- konlpy 라이브러리 설치
!pip install konlpy
- 불용어처리, 토큰화, 어간추출 수행
import konlpy #한글처리 라이브러리
from konlpy.tag import Okt #한글 토큰화 라이브러리
from tqdm import tqdm #작업진행률 표시 라이브러리
okt=Okt()
X_train=[]
#불용어 리스트
stopwords=['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
#반복문으로 영화 리뷰에 대해 불용어 처리, 토큰화, 어간추출 수행
for sen in tqdm(train_data['document']):
tmp_x=[]
#okt.morphs(): 한글 형태소 분리기
#stem=True: 어간추출 기능 포함
tmp_x=okt.morphs(sen, stem=True)
#불용어 처리
#토큰들을 하나씩 불러와서(for word in tmp_x )
#불용어가 아닌 경우만 리스트에 저장하고(if word not in stopwords)
#리스트를 tmp_x에 저장
tmp_x=[word for word in tmp_x if word not in stopwords]
X_train.append(tmp_x)
- 수행결과 저장하기(pickle)
#pickle: 사용하는 데이터 타입 그대로 저장하는 도구
import pickle
#with: 파일객체를 자동으로 닫는 기능
#wb: write, binary(바이너리 형태로 쓸 수 있음)
with open("./data/X_train.txt", 'wb') as f:
#파일로 해당 내용 저장
pickle.dump(X_train, f)
- 저장된 데이터 불러오기
with open("./data/X_train.txt", "rb") as f:
X_train=pickle.load(f)
5. 인코딩: 분리된 단어를 숫자로 변환
- 단어의 빈도 수 분석(BoW, CountVectorizer, TF-IDF)
- 빈도 수 순으로 정렬
- 정렬된 순서대로 1부터 인덱스 부여
- 해당 인덱스들로 단어 치환
from tensorflow.keras.preprocessing.text import Tokenizer
#빈도수가 높은 상위 35,000개 단어만 사용하도록 설정
max_feature=35000
tokenizer=Tokenizer(num_words=max_feature)
#인코딩을 위한 분석(빈도 수 분석)
tokenizer.fit_on_texts(X_train)
#정렬, 인덱스 부여, 인덱스로 문장 변환(1부터 부여함, 0은 데이터가 없는 것)
X_train=tokenizer.texts_to_sequences(X_train)
6. 인코딩한 문장을 같은 길이로 변경(Padding)
- 특성 데이터 인코딩(문제데이터)
from tensorflow.keras.preprocessing.sequence import pad_sequences
#문장의 길이
max_word=30
#학습데이터의 문장길이 동일하게 변경
X_train=pad_sequences(X_train, maxlen=max_word)
- 라벨 데이터 저장(정답데이터)
y_train=train_data['label']
7. 신경망의 Embedding 층을 이용하여 Word Embedding 사전벡터 생성, 신경망 설계
- Embedding: 인코딩된 데이터를 각 단어들 간의 유사성과 거리 관계로 벡터로 공간에서 표현한 층, 단어들 간의 관계를 정의하는 층(특성추출기)
- LSTM(Long short-term memory)
-LNN은 활성화 함수 sigmoid나 tahh 사용
-시간이 지날수록 이전의 중요한 데이터가 사라지는 문제(기울기 소실 문제)해결
-LSTM의 속도를 개선한 버전: GRU

from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
model1=Sequential()
#Embedding층
#max_feature: 사용할 최대 단어 수
#dim: 한 단어가 연결되는 단어의 수
#input_length: 입력데이터의 길이
model1.add(Embedding(max_feature, 100, input_length=max_word))
model1.add(LSTM(128))
#Dense
model1.add(Dense(1, activation='sigmoid'))
model1.summary()
8. 학습/평가/예측
- 학습방법 및 평가방법 설정
model1.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
- 모델 학습
model1.fit(X_train, y_train,
validation_split=0.2,
batch_size=50,
epochs=1
)
- 모델 예측
#예측
import numpy as np
pred=model1.predict(X_train[:1000])
print(train_data.loc[10])
print(pred[10])
[RNN]
- 텍스트는 이어진 데이터(Sequential data)로 구성→단어가 순서대로 입력되어야 함
- 과거에 입력된 데이터와 나중에 입력된 데이터 사이의 관계(시계열 분석)를 고려하는 것
- 데이터를 순서대로 입력했을 때 이전 입력데이터를 저장해서 저장데이터의 중요도 판단→가중치 부여해서 학습에 반영

- 반복적이고 순차적인 데이터 학습에 특화된 인공신공망의 종류
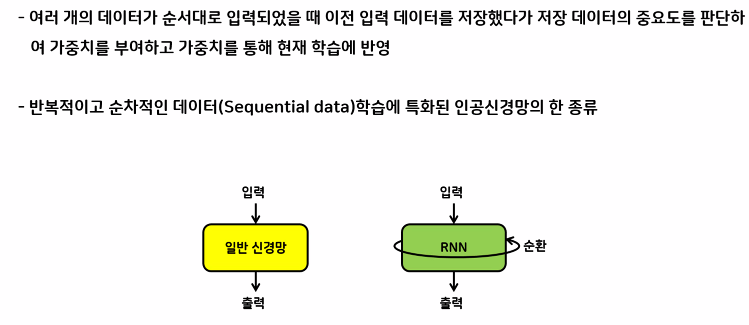
- 특징: 시간에 따른 순서 기억→신경망의 출력이 다른 신경망과 연결
- 단점: 처음 시작한 Weight값이 학습이 될수록 1보다 작은 값이 곱해져 상쇄됨(Vanishing Gradient Problem), 즉 중요한 데이터가 시간이 지날수록 데이터가 사라짐



'코딩 > 딥러닝' 카테고리의 다른 글
| [DL]10. 객체 탐지 (0) | 2023.10.04 |
|---|---|
| [DL]8. 소리데이터 분석 (2) | 2023.09.22 |
| [DL]7. 과대적합 제어 및 전이학습 (1) | 2023.09.21 |
| [DL]6. CNN (0) | 2023.09.20 |
| [DL]5. 오차 역전파 (0) | 2023.09.15 |